��(j��)FPGAϵ�y(t��ng)�O(sh��)Ӌ(j��)��Ҫ�о������O(sh��)Ӌ(j��)�����W(xu��)���㷨�͔�(sh��)��(j��)�Y(ji��)��(g��u)�������Z�Ժͳ����wϵ�Y(ji��)��(g��u)�cӲ��߉�Լ��O(sh��)Ӌ(j��)�c��(sh��)�F(xi��n)�����傀(g��)�P(gu��n)�I���}��ֻ�ЌW(xu��)��(x��)���պ��@5��(g��)�����֪�R(sh��)������������@�傀(g��)������P(gu��n)ϵ�����������Ŀ��w�ϰ���ȫϵ�y(t��ng)���O(sh��)Ӌ(j��)���M��Ҫ��ĸ����ܔ�(sh��)��ϵ�y(t��ng)��
FPGAϵ�y(t��ng)�O(sh��)Ӌ(j��)��(sh��)�|(zh��)����һ��(g��)ͬ���r(sh��)��ϵ�y(t��ng)���O(sh��)Ӌ(j��)���������Օr(sh��)��ĸ�������M(j��n)�����_�����ĕr(sh��)��s�����nj�(sh��)�F(xi��n)������ϵ�y(t��ng)����Ҫ���C�����n�̰���"�ĺ��^���^����플ӵ���"��ϵ�y(t��ng)�O(sh��)Ӌ(j��)ԭ�t����"�r(sh��)������c�O(sh��)Ӌ(j��)��Timing Analyzing and Design��"�����������Տ�"�����܃�(n��i)��߉�O(sh��)Ӌ(j��)"��"�����ⲿ�ӿ��O(sh��)Ӌ(j��)"�ٵ�"FPGAǶ��ʽϵ�y(t��ng)"���������̽ӑ��"FPGA��FPGA��(sh��)��ϵ�y(t��ng)"��"FPGA�O(sh��)Ӌ(j��)�����c�r(sh��)���Ք�"��"Virtex-4��Virtex-5��(j��)�YԴ"��"FPGA����I/O�ӿ��O(sh��)Ӌ(j��)"�Լ�FPGAǶ��ʽϵ�y(t��ng)�_�l(f��)�ĸ�(j��)�����c���g(sh��)5�����}���n�̃�(n��i)�ݽY(ji��)��������(gu��)���P(gu��n)ԭ����Ӗ(x��n)�n�̺���Ӗ(x��n)�v���Ŀ��н̌W(xu��)��(sh��)�`����Փ�S������(sh��)�(y��n)���������зdz���(qi��ng)��ϵ�y(t��ng)�Ժ͌�(sh��)���ԣ���������(d��o)�W(xu��)�T�������FPGA��(sh��)��ϵ�y(t��ng)�O(sh��)Ӌ(j��)ˮƽ���Ķ��܉�����(chu��ng)���O(sh��)Ӌ(j��)���s���_�l(f��)�r(sh��)�g�������_�l(f��)�ɱ���
�������k��λ���Ї�(gu��)�߿Ƽ��a(ch��n)�I(y��)���о���(hu��)��̖(h��o)̎�팣��ί�T��(hu��)
�������ޕr(sh��)�g��2010��06��10-13��(09��?q��ng)?b��o)��)
�ġ��� �c(di��n)���� �������w���c(di��n)��·���DԔҊ��(b��o)��֪ͨ��
�塢��Ӗ(x��n)��(du��)��
�n���m����ʹ��FPGA�����M(j��n)�п��кͮa(ch��n)Ʒ�_�l(f��)�ľ����е�ˮƽ�Ĺ��̼��g(sh��)�ˆT��Ҳ�m�������P(gu��n)���I(y��)�I(l��ng)������ஔ(d��ng)ˮƽ�Ľ̎����о�����
��������ƽ�_(t��i)
��Ӗ(x��n)�n��ʹ�õ�����ܛӲ����������Ӗ(x��n)���ṩ������(j��)��Ӗ(x��n)�r(sh��)�g�͵��c(di��n)�IJ�ͬ��ܛӲ���汾��(hu��)����׃������Ӗ(x��n)�������ԃ�(y��u)�ݵăr(ji��)����?q��)W�T�ṩ����Xilinx XC3S500E�ĸ�(j��)�_�l(f��)��һ�K���Է���W(xu��)�T�ڌW(xu��)��(x��)�Y(ji��)�����^�m(x��)�����о���������Ӗ(x��n)ʹ�õ�Ӳ��ƽ�_(t��i): XUPV2Pro��(sh��)�(y��n)�塣
�ߡ����n��V
1��FPGA��FPGA��(sh��)��ϵ�y(t��ng)
����(ji��)ͨ�^��(du��)��(sh��)����̖(h��o)̎����Ӌ(j��)�㣨Computing�����㷨�͔�(sh��)��(j��)�Y(ji��)��(g��u)�������Z�Ժͳ����wϵ�Y(ji��)��(g��u)��Ӳ��߉�Լ��O(sh��)Ӌ(j��)�����W(xu��)�Ļ������������֮�g�P(gu��n)ϵ�Ľ�B��ʹ�W(xu��)�T�ĸ��ߵČӴ���ȥ����FPGA��(sh��)��ϵ�y(t��ng)���O(sh��)Ӌ(j��)���}��ͨ�^����(ji��)��ϣ���W(xu��)�T�܉�����F(xi��n)�����ϵ�y(t��ng)����������P(gu��n)ϵ��ģ�Mϵ�y(t��ng)�c��(sh��)��ϵ�y(t��ng)���P(gu��n)ϵ/ܛ���cӲ�����P(gu��n)ϵ/ͬ��ϵ�y(t��ng)�c����ϵ�y(t��ng)���P(gu��n)ϵ��������FPGA�Ļ����Y(ji��)��(g��u)�ͼ��g(sh��)���c(di��n)��
2��FPGA�O(sh��)Ӌ(j��)�����c�r(sh��)���Ք�
FPGAϵ�y(t��ng)�O(sh��)Ӌ(j��)��(sh��)�|(zh��)����һ��(g��)ͬ���r(sh��)��ϵ�y(t��ng)���O(sh��)Ӌ(j��)�������������Օr(sh��)��ĸ������ʹ�Õr(sh��)��s�����ߌ�(du��)�O(sh��)Ӌ(j��)�M(j��n)�����_�ġ������ļs�����nj�(sh��)�F(xi��n)������ϵ�y(t��ng)����Ҫ���C������(ji��)�nj�(du��)FPGA�Y(ji��)��(g��u)�YԴ���O(sh��)Ӌ(j��)���̺��O(sh��)Ӌ(j��)���ߵĚw�{�����Y(ji��)�c���A��ʹ�W(xu��)�T�^����F(xi��n)��FPGA�O(sh��)Ӌ(j��)���g(sh��)�Č�(sh��)�|(zh��)���Ķ�������FPGA��(j��)�O(sh��)Ӌ(j��)���g(sh��)���»��A(ch��)��
��Ҫ��(n��i)�����£���������FPGA�O(sh��)Ӌ(j��)���(y��n)�C���̣����վC�ϣ�Synthesize���IJ�ͬ���Ԍ�(du��)���ܸ��Ƶ�Ӱ푣�ͨ�^ʹ�ø�(j��)��(sh��)�F(xi��n)��Implement�����������O(sh��)Ӌ(j��)���ܣ�����ȫ�֕r(sh��)��s�����M(j��n)һ���W(xu��)��(x��)�ض�·���r(sh��)��s������ʹ�üs���������_�O(sh��)��ϵ�y(t��ng)�s�����\(y��n)���o�B(t��i)�r(sh��)��������ߣ�Timing Analyzer���͕r(sh��)���Ք����̽�Q�r(sh��)���}�������������FPGA��ܛӲ���f(xi��)ͬϵ�y(t��ng)�O(sh��)Ӌ(j��)�h(hu��n)����ISE��EDK��SysGen����
3��Virtex-4��Virtex-5��(j��)�YԴ
�W(xu��)��(x��)�������µ�FPGA�O(sh��)Ӌ(j��)���������������е�FPGA�O(sh��)Ӌ(j��)���ߌ�(du��)��(sh��)�F(xi��n)�����ܵ�FPGA��(sh��)��ϵ�y(t��ng)���x�ش���(ji��)����һ��(ji��)���c(di��n)�P(gu��n)עFPGA�O(sh��)Ӌ(j��)�I(l��ng)����¼��g(sh��)��
Xilinx Virtex-4��Virtex-5 FPGAоƬ��Ŀǰ�����M(j��n)�Ŀɾ���߉����������(ji��)��BVirtex-4��Virtex-5 FPGA�ṩ�����YԴ�����O(sh��)Ӌ(j��)�������e�Ǖr(sh��)�ϵ�y(t��ng)���O(sh��)Ӌ(j��)�������O(sh��)Ӌ(j��)���ɡ�Virtex-4��Virtex-5�����ܵ�Դͬ���YԴ�ͼ��g(sh��)���QоƬ�g����ͨ���ṩ���������C������(ji��)���c(di��n)�W(xu��)��(x��)����Virtex-4��Virtex-5�� �r(sh��)��O(sh��)Ӌ(j��)��Դͬ�����g(sh��)�������IO�ӿ��O(sh��)Ӌ(j��)�������»��A(ch��)��
4��FPGA����I/O�ӿ��O(sh��)Ӌ(j��)
FPGAƬ��(n��i)�����l�ʿ����_(d��)��500MHz�����Ҿ��Џ�(qi��ng)��IJ���̎����������оƬ�g�ӿ��ٶ��ѽ�(j��ng)�ɞ������ϵ�y(t��ng)��ƿ�i������ϵ�y(t��ng)��Ҫ�����N�r(sh��)犽Y(ji��)��(g��u)����ȫ�֕r(sh��)�ϵ�y(t��ng)��Դͬ���r(sh��)�ϵ�y(t��ng)����ͬ���r(sh��)�ϵ�y(t��ng)������(ji��)���c(di��n)�W(xu��)��(x��)Դͬ���r(sh��)犼��g(sh��)��ԭ���͑�(y��ng)�ã����д�����(sh��)���������W(xu��)�T������Փ�͌�(sh��)�`�ɂ�(g��)������������Դͬ�����g(sh��)�ڸ��ٽӿڼ��g(sh��)�еđ�(y��ng)�ã��W(xu��)��(x��)ʹ���o�B(t��i)�r(sh��)��������߷������ٽӿڵĕr(sh��)���}���W(xu��)��(x��)ʹ��Դͬ�����g(sh��)��Դͬ���YԴ��Q���ٽӿڵĕr(sh��)���}��
��Ҫ��(n��i)�����£��W(xu��)��(x��)Դͬ������I/O�ӿڼ��g(sh��)��ʹ�Õr(sh��)����������ҽӿڕr(sh��)��ʧ��ԭ�����O(sh��)Ӌ(j��)�ԝM��r(sh��)��Ҫ�����W(xu��)��(x��)���ٶ�ͨ������ADC�cFPGA�ӿ��O(sh��)Ӌ(j��)������DSPоƬ�cFPGA�ӿ��O(sh��)Ӌ(j��)��
5��FPGAǶ��ʽϵ�y(t��ng)��(j��)�����c���g(sh��)��Փ���n
�S��FPGA���g(sh��)�İl(f��)չ����FPGA�ό�(sh��)�F(xi��n)�ɾ���Ƭ��ϵ�y(t��ng)��PSOC���ڼ��g(sh��)���ѳɞ���ܡ�����FPGA��PSOCϵ�y(t��ng)�_�l(f��)�ѳɞ�ĿǰFPGA��(y��ng)�õ�һ��(g��)���c(di��n)�����ǻ���FPGA��Ƕ��ʽϵ�y(t��ng)�_�l(f��)��(du��)ʹ���ߵ�֪�R(sh��)Ҫ����^�ߣ����̏�(f��)�s�����P(gu��n)�Y�ϲ��࣬�@Щ���ɞ�Ŀǰ�_�l(f��)FPGAǶ��ʽϵ�y(t��ng)��ƿ�i���}��
�����փ�(n��i)����FPGAǶ��ʽϵ�y(t��ng)�_�l(f��)����(j��)�����ڵļ��ܞ���A(ch��)��Ҫ��W(xu��)�T�߂������Ƕ��ʽϵ�y(t��ng)�_�l(f��)�Լ�C�Z��֪�R(sh��)����Ҫ���@��Ƕ��ʽϵ�y(t��ng)�ĸ�(j��)�������̑�(y��ng)��չ�_�v�ڣ����w������Picoblaze��MicroBlaze��PowerPC�@�ɴ������Picoblaze��һ��(g��)8λ��MCU��(n��i)�ˣ���(y��ng)�÷�ʽ�dz��`�MicroBlaze��PowerPC�����(j��)��32λ̎���(n��i)�ˣ�ǰ�ߞ�ܛ�ˣ����ߞ�Ӳ�ˣ��m����ɏ�(f��)�s��PSOCϵ�y(t��ng)��(sh��)�F(xi��n)��
PicoBlaze 8λ̎������Xilinx��˾��Virtexϵ��FPGA��Spartanϵ��FPGA��CoolRunner-IIϵ��CPLD�����O(sh��)Ӌ(j��)Ƕ��ʽ����IP Core������Q�˳������a�ɾ��̠�B(t��i)�C(j��)��KCPSM���Ć��}���@һģ�Kֻռ��SpartanIIE��76��(g��)С�^(q��)��slice������߀����һ��(g��)���ڴ惦(ch��)ָ�����Block RAM�M�ɵ�ROM�����ɴ惦(ch��)256�lָ��ڌ�(sh��)�H�������H��"�ăɓ�ǧ��"֮��Ч
��(du��)��MicroBlaze��PowerPCϵ�y(t��ng)���t��ע�ش惦(ch��)�����g(sh��)��ϵ�y(t��ng)���ٲ��ԡ��Ñ��Զ��x���O(sh��)��ܛ���_�l(f��)������(d��ng)���d����Boot loader���O(sh��)Ӌ(j��)������ϵ�y(t��ng)��ܛӲ���f(xi��)ͬ�_�l(f��)�Ⱥ��Ć��}��ͬ�r(sh��)���ڌ�(sh��)�H�У����FPGA�IJ����������t���Ԍ�MicroBlaze��PowerPC����"���X"����FPGA��߉�YԴ�t��Ч��"���K����֫�Լ����"�Ⱥ��ĽM����ֻ�б˴��ЙC(j��)�Y(ji��)�ϲ����γɸ�Ч��ϵ�y(t��ng)������ڌW(xu��)��(x��)����FPGA��Ƕ��ʽϵ�y(t��ng)�_�l(f��)�У����ܺ�(ji��n)���J(r��n)��Ƕ��ʽ����ȫ�����@�͵��͵�MCU��ARM�Լ�DSPǶ��ʽϵ�y(t��ng)�������|(zh��)�^(q��)�e��������MicroBlaze��PowerPC��(n��i)�ˁ��v����͂��y(t��ng)��Ƕ��ʽϵ�y(t��ng)��(sh��)��ͨ�ġ�
��ˣ����n�̻���FPGAƽ�_(t��i)���W(xu��)�T����һ��(g��)����V韵�ҕ�ǣ�ͬ�r(sh��)��(du��)����������͵�Ƕ��ʽ��(y��ng)��ϵ�y(t��ng)�ܘ�(g��u)��(hu��)��Ҳ�и�������⡣
]]>
2.4 ����߉�W(w��ng)�j(lu��)
����߉�W(w��ng)�j(lu��)�ǻ����Ԍ�(du��)ż����(sh��)����У�(y��n)߉�W(w��ng)�j(lu��)��һ��(g��)���M(j��n)��׃���ǽ���ģ�ӛ��![]() ��x�ڃɂ�(g��)�B�m(x��)�ĕr(sh��)�g�g���(n��i)��ȡ��ֵ���a(b��)��
��x�ڃɂ�(g��)�B�m(x��)�ĕr(sh��)�g�g���(n��i)��ȡ��ֵ���a(b��)��
��(du��)����һ��(g��)�_�P(gu��n)����(sh��)![]() �������O(sh��)
�������O(sh��)![]() �ǽ�����M(j��n)��׃������������ͬ������ģ��t���ݔ��ʸ���ɱ�ʾ��
�ǽ�����M(j��n)��׃������������ͬ������ģ��t���ݔ��ʸ���ɱ�ʾ��![]() ����ݔ���ɱ�ʾ��
����ݔ���ɱ�ʾ��![]() ��Ҫʹݔ��׃��Ҳ�ǽ���ģ���횝M��
��Ҫʹݔ��׃��Ҳ�ǽ���ģ���횝M��![]() ���@Ȼ��g������Ԍ�(du��)ż����(sh��)�����ý���߉�W(w��ng)�j(lu��)���@��(g��)���c(di��n)�����ԙz�y(c��)��ϵ�y(t��ng)��һ���ֹ��ϡ�
���@Ȼ��g������Ԍ�(du��)ż����(sh��)�����ý���߉�W(w��ng)�j(lu��)���@��(g��)���c(di��n)�����ԙz�y(c��)��ϵ�y(t��ng)��һ���ֹ��ϡ�
�� ���(y��n)�W(w��ng)�j(lu��)��(sh��)�F(xi��n)����
��(du��)��һЩ���^��(ji��n)�εđ�(y��ng)�È�(ch��ng)�ϣ����Ô�(sh��)��߉�����M(j��n)���O(sh��)Ӌ(j��)��ʹ��SSI��MSI�����·���ɷ���ؘ�(g��u)����У�(y��n)�W(w��ng)�j(lu��)������(sh��)�H���e(cu��)ϵ�y(t��ng)�dz���(f��)�s���漰����߉�O(sh��)Ӌ(j��)�����Բ��Â��y(t��ng)�Ĕ�(sh��)��߉�O(sh��)Ӌ(j��)���������H�����������׳����e(cu��)�������ĺ��ܷ��涼�����㡣ʹ������O(sh��)Ӌ(j��)Ӳ�������Z��VHDL����Verilog HDL��(du��)�·�����M(j��n)����������FPGA��CPLD������(sh��)�F(xi��n)��У�(y��n)�W(w��ng)�j(lu��)�DZ��^�F(xi��n)��(sh��)�ģ���(du��)�ڴ��������a(ch��n)���Ɍ�VHDL�������·�Ͱ댧(d��o)�w�����S�M(j��n)���������a(ch��n)��VHDLӲ�������Z�Ԍ�(sh��)�F(xi��n)��У�(y��n)�W(w��ng)�j(lu��)�IJ��E���£�
�ٽ�����У�(y��n)�W(w��ng)�j(lu��)�Ĺ���ģ�͡���(du��)ϵ�y(t��ng)��ݔ�룯ݔ������B(t��i)�D(zhu��n)�Q����̖(h��o)���f���M(j��n)��Ԕ��(x��)���f����
����VHDL�Z�Ի�Verilog HDL�Z�Ԍ�(du��)�·�����M(j��n)����������(du��)��(f��)�sϵ�y(t��ng)�ɲ��Ó��E϶��?sh��)��O(sh��)Ӌ(j��)��������ϵ�y(t��ng)�ֽ�ɲ�ͬ�Ӵεġ������^��(ji��n)�ε�ģ�K������VHDL�Z�Ԍ�(du��)ϵ�y(t��ng)�����M(j��n)�з��������p��ϵ�y(t��ng)������ɵ��e(cu��)�`��
�ی�(du��)��ͬ�Ӵε�ģ�K�M(j��n)�й��ܷ��棬�ԙz�(y��n)��ģ�K�O(sh��)Ӌ(j��)�����_�ԣ����(du��)����(g��)ϵ�y(t��ng)�M(j��n)�й��ܷ��棬�����ų�ϵ�y(t��ng)�O(sh��)Ӌ(j��)�е��e(cu��)�`��
����VHDL��Verilog HDL�C�Ͼ��g����(du��)�O(sh��)Ӌ(j��)�õ�ϵ�y(t��ng)�M(j��n)�о��g����(j��ng)�^߉����(ji��n)���C�ϲ��������ɿɌ�(du��)FPG A��CPLD���̵Ĕ�(sh��)��(j��)�ļ���
����(sh��)��(j��)�ļ�ͨ�^����������FPGA��CPLD���M(j��n)�Ќ�(sh��)�H�y(c��)ԇ�����y(c��)ԇ��(sh��)��(j��)�M���O(sh��)Ӌ(j��)Ҫ�t�_�l(f��)������ɣ���t���D(zhu��n)�������M(j��n)�Йz����O(sh��)Ӌ(j��)��
������У�(y��n)���g(sh��)����Ч��������e(cu��)ϵ�y(t��ng)�Ŀɿ��ԣ��S�������·���g(sh��)���w�ٰl(f��)չ���Ɍ�һЩ��У�(y��n)����ģ�K�M(j��n)�з��b�������(bi��o)��(zh��n)��Ԫʹ�ã���ģ�K��(j��)��������e(cu��)ϵ�y(t��ng)�Ŀɿ��ԡ����ø�(j��)�Z�Ժ�FPGA��CPLD�_�l(f��)���e(cu��)ϵ�y(t��ng)������Ҫ�ĬF(xi��n)��(sh��)���x������Ч�s���_�l(f��)���ڣ������_�l(f��)�ɱ������ϵ�y(t��ng)�ɿ��ԣ���(y��ng)�ڹ����O(sh��)Ӌ(j��)�м����ƏV��(y��ng)
�O(sh��)�M��߉�W(w��ng)�j(lu��)���_ݔ��ʸ����![]() ���tʸ�����g
���tʸ�����g![]() �Q���e(cu��)�`ݔ����g��ӛ��
�Q���e(cu��)�`ݔ����g��ӛ��![]() �����g
�����g![]() ���Q���Ƿ����e(cu��)�`ݔ����g��ӛ��
���Q���Ƿ����e(cu��)�`ݔ����g��ӛ��![]() �������_ݔ����g
�������_ݔ����g![]() ��(j��ng)�·G����S(F)�Юa(ch��n)��һ��(g��)�ӿ��g���@��(g��)�ӿ��g�Q�����_ݔ�����g��ӛ��
��(j��ng)�·G����S(F)�Юa(ch��n)��һ��(g��)�ӿ��g���@��(g��)�ӿ��g�Q�����_ݔ�����g��ӛ��![]() ��ͬ�ӣ���(du��)�ںϷ�ݔ��
��ͬ�ӣ���(du��)�ںϷ�ݔ��![]() ���ɽM��߉�W(w��ng)�j(lu��)��ӳ���Ϸ�ݔ�����g
���ɽM��߉�W(w��ng)�j(lu��)��ӳ���Ϸ�ݔ�����g![]() ��Ҳ��ݔ��ʸ�����gS(F)���Ӽ���ͬ�ӣ����g
��Ҳ��ݔ��ʸ�����gS(F)���Ӽ���ͬ�ӣ����g![]() ���Q���e(cu��)�`ݔ�����g��ӛ��
���Q���e(cu��)�`ݔ�����g��ӛ��![]() �����g
�����g![]() ���Q��Ƿ����e(cu��)�`ݔ�����g����ʾ��
���Q��Ƿ����e(cu��)�`ݔ�����g����ʾ��![]() ������ݔ��֮�g�������P(gu��n)ϵ��
������ݔ��֮�g�������P(gu��n)ϵ��
![]()
�����漯��֮�g���P(gu��n)ϵ�҂����Կ�������(du��)�ڟo���ϽM�ϾW(w��ng)�j(lu��)�����_ݔ�룬��ݔ����(y��ng)�������_ݔ�����g![]() �С�ͨ�^��(du��)�W(w��ng)�j(lu��)��ݔ���ɲ����ж�ϵ�y(t��ng)�����Ƿ��������o���Д�ijЩ���ϣ�����(d��ng)�W(w��ng)�j(lu��)�l(f��)�����ϕr(sh��)���ɷֳ����N��r���ٷǷ����e(cu��)�`ݔ�뱻ӳ���
�С�ͨ�^��(du��)�W(w��ng)�j(lu��)��ݔ���ɲ����ж�ϵ�y(t��ng)�����Ƿ��������o���Д�ijЩ���ϣ�����(d��ng)�W(w��ng)�j(lu��)�l(f��)�����ϕr(sh��)���ɷֳ����N��r���ٷǷ����e(cu��)�`ݔ�뱻ӳ���![]() ����ݔ��
����ݔ��![]() ��ӳ��ɞ�
��ӳ��ɞ�![]() ����
����![]() ӳ��
ӳ��![]() ���Ѳ������_��ӳ���P(gu��n)ϵ��Ҳ�����fݔ��ݔ���P(gu��n)ϵ�l(f��)����׃������(du��)��һ��(g��)�߿ɿ����e(cu��)ϵ�y(t��ng)���f������܉��Ա��^�ߵĹ��ϸ��w�ʁ�z�y(c��)����������e(cu��)�������һ�ă�(n��i)�z������ʹϵ�y(t��ng)���r(sh��)��ȡ��ʩ�����x���ϣ�����Ӱ표pС������ȡ�������e(cu��)�`�У��ڢ�͵ڢ���c�ڢ�����Ҫ�Ùz�y(c��)һЩ����Ч�z�y(c��)�ڢ���e(cu��)�`�����ϵ�y(t��ng)���ϸ��w�ʵ��P(gu��n)�I��ֻ���O(sh��)Ӌ(j��)����(du��)��������e(cu��)�`�z���ʾ��^�ߵęz�e(cu��)ϵ�y(t��ng)�����ܱ��Cϵ�y(t��ng)���^�ߵĿɿ��ԡ�
���Ѳ������_��ӳ���P(gu��n)ϵ��Ҳ�����fݔ��ݔ���P(gu��n)ϵ�l(f��)����׃������(du��)��һ��(g��)�߿ɿ����e(cu��)ϵ�y(t��ng)���f������܉��Ա��^�ߵĹ��ϸ��w�ʁ�z�y(c��)����������e(cu��)�������һ�ă�(n��i)�z������ʹϵ�y(t��ng)���r(sh��)��ȡ��ʩ�����x���ϣ�����Ӱ표pС������ȡ�������e(cu��)�`�У��ڢ�͵ڢ���c�ڢ�����Ҫ�Ùz�y(c��)һЩ����Ч�z�y(c��)�ڢ���e(cu��)�`�����ϵ�y(t��ng)���ϸ��w�ʵ��P(gu��n)�I��ֻ���O(sh��)Ӌ(j��)����(du��)��������e(cu��)�`�z���ʾ��^�ߵęz�e(cu��)ϵ�y(t��ng)�����ܱ��Cϵ�y(t��ng)���^�ߵĿɿ��ԡ�
�� ��У�(y��n)�W(w��ng)�j(lu��)�ĽY(ji��)��(g��u)
��У�(y��n)�W(w��ng)�j(lu��)�����ڟo�κ���Ӽ���(l��)����r�����Ԅ�(d��ng)�z�y(c��)���(n��i)���Ƿ���ڹ��ϣ��@Щ���ϻ��������ԵĻ��Ǖ��r(sh��)�Եġ��O(sh��)Ӌ(j��)��У�(y��n)�W(w��ng)�j(lu��)����Ҫ���g(sh��)�Йz�e(cu��)���a���g(sh��)�������Ԍ�(du��)ż����(sh��)�Ľ���߉���g(sh��)������߉���g(sh��)�������ڌ�(du��)ż����(sh��)�Ļ��a(b��)߉���g(sh��)��߀�л��ڶ�ֵ߉�Č�(sh��)�F(xi��n)�����������҂���ҪӑՓһЩ��(sh��)�õČ�(sh��)�F(xi��n)������
2.1 �p܉�aУ�(y��n)��
�p܉�aУ�(y��n)����ԭ��D��D����ʾ��
ݔ��ʸ����![]() ������
������![]() ����i=1,2)��ݔ��ʸ����
����i=1,2)��ݔ��ʸ����![]() �ҝM�㣺
�ҝM�㣺

![]() ��
��![]() ��У�(y��n)���o���ϡ�
��У�(y��n)���o���ϡ�
�����p܉�aУ�(y��n)�����������c(di��n)���O(sh��)Ӌ(j��)һ��(du��)ż�M��߉�W(w��ng)�j(lu��)��ʹ��ݔ������![]() ��
��![]() ǡ�÷��࣬��
ǡ�÷��࣬��![]() ��
��![]() �ӵ��p܉�aУ�(y��n)��ݔ��ˣ�����(j��)
�ӵ��p܉�aУ�(y��n)��ݔ��ˣ�����(j��)![]() �Ϳ����ж�ϵ�y(t��ng)�Ƿ�l(f��)�����ϡ�
�Ϳ����ж�ϵ�y(t��ng)�Ƿ�l(f��)�����ϡ�
2.2 �ɷִaУ�(y��n)��
�ɷִaУ�(y��n)���ĽY(ji��)��(g��u)��D����ʾ��У�(y��n)����ݔ��ʸ����![]() )��ʸ��
)��ʸ��![]() ��
��![]() �քe��(du��)��(y��ng)�ɷִa����Ϣ������У�(y��n)���������У���Ϣ�������Ȟ�
�քe��(du��)��(y��ng)�ɷִa����Ϣ������У�(y��n)���������У���Ϣ�������Ȟ�![]() ��У�(y��n)�����Č��ȣ���1+K=n, n=��Y����У�(y��n)λ�����·����(j��)��Ϣλ
��У�(y��n)�����Č��ȣ���1+K=n, n=��Y����У�(y��n)λ�����·����(j��)��Ϣλ![]() ��������У�(y��n)λW�����p܉�aУ�(y��n)�����^W�c
��������У�(y��n)λW�����p܉�aУ�(y��n)�����^W�c![]() ��һ���ԣ��ڟo���ϵ���r�£�У�(y��n)����ݔ��
��һ���ԣ��ڟo���ϵ���r�£�У�(y��n)����ݔ��![]() ָʾݔ��ʸ������Ч�ԡ�����Ķ����o���ˈD����ȫ��У�(y��n)�ɷִaУ�(y��n)���Ę�(g��u)��l����
ָʾݔ��ʸ������Ч�ԡ�����Ķ����o���ˈD����ȫ��У�(y��n)�ɷִaУ�(y��n)���Ę�(g��u)��l����
������Ƕ��ʽ�Ј�(ch��ng)�����������ĵͼ�(j��)Ӳ����ܛ�����ߣ�ͬ�r(sh��)�S��Ƕ��ʽ�O(sh��)Ӌ(j��)��Ӳ�����g(sh��)(���̎������FPGA�ȵ�)������ߵď�(f��)�s�ԣ�Ҫʹ�ìF(xi��n)�й����M(j��n)�п���ԭ���O(sh��)Ӌ(j��)�����y�ġ�
�������˹�(ji��)ʡ��ܛ��ԭ���_�l(f��)�л��M(f��i)�ĕr(sh��)�g�ͽ��X����(y��ng)��(d��ng)�x���܉����ֵӹ����Ĺ��ߡ�ʹ��LabVIEW���̹����M(j��n)�ЈD�λ�ϵ�y(t��ng)�O(sh��)Ӌ(j��)���Ñ��ṩ�ˏ�(qi��ng)���ֱ�^���_�l(f��)�h(hu��n)����ʹ�Ñ��܉�ֱ���_ʼ�M(j��n)��ԭ���_�l(f��)��LabVIEW���ЈD�λ����ԣ����Д�(sh��)ǧ��(g��)��(n��i)������(sh��)�K������������̖(h��o)̎������(j��)���ơ�ͨ�š���(sh��)��(j��)�ɼ���ӛ䛵��΄�(w��)�С����⣬LabVIEW�܉��ڴ�����(f��)�s��Ӳ��Ŀ��(bi��o)���\(y��n)�У��Ķ���c��(sh��)�r(sh��)̎����ֱ��FPGA����?y��n)��Ñ�����ʹ��LabVIEW��(du��)FPGA�M(j��n)�о��̣����Է������ԭ��ϵ�y(t��ng)��ʹ���@��(g��)���g(sh��)�����o�����M(f��i)�������_�l(f��)�r(sh��)�g��
����ʹ�à�B(t��i)�D�ļ��ϵ��O(sh��)Ӌ(j��)�M(j��n)���^��
���������(sh��)�O(sh��)Ӌ(j��)���뷨�Ǐļ����_ʼ�ġ��oՓ�nj��ڲͽ�����߀�Ǹ���ʽ�ĕ���Ӌ(j��)�����ļ���ƽ��(w��n)�^�ɵ�ܛ�������������_ʼ�����O(sh��)Ӌ(j��)�����̎����O(sh��)Ӌ(j��)Ƕ��ʽϵ�y(t��ng)ܛ���wϵ�Y(ji��)��(g��u)�У��ѽ�(j��ng)ʹ�à�B(t��i)�D�����ˡ���20���o(j��)90�������B(t��i)�D���J(r��n)���ǽy(t��ng)һ��ģ�Z��(UML)Ҏ(gu��)�����О��D���V�����ڌ�(du��)Ƕ��ʽϵ�y(t��ng)�M(j��n)�н�ģ��
����ʹ��LabVIEW��B(t��i)�Dģ�K���Ñ�����ʹ�à�B(t��i)�D��D�O(sh��)Ӌ(j��)ܛ���M����ʹ�Ô�(sh��)��(j��)���D�λ����̶��x��B(t��i)�О���^��߉���D1չʾ���Ñ���Ώļ��ϵĠ�B(t��i)�D�^�ɵ�LabVIEW��B(t��i)�D��
����
�����D1 �ļ��ϵĠ�B(t��i)�D�^�ɵ�LabVIEW��B(t��i)�Dģ�K
���������B�ӵ�I/O�Լ�Ƕ��ʽ������
������(du��)�ڴ����(sh��)��(sh��)�r(sh��)Ƕ��ʽ��(y��ng)�ö��ԣ��B�ӵ���(sh��)�H��I/O�DZ�횵ġ���ˣ��ڄ�(chu��ng)��ԭ��ϵ�y(t��ng)�r(sh��)��ʹ�ù��߿��ٵ��B�ӵ�����������(d��ng)����ʮ����Ҫ�ġ�NI�ṩ���S���İ忨��(j��)���bӲ�������а����Ñ��c�κ������M(j��n)�н�����ģ�M�͔�(sh��)��I/O���e�����ԣ�NI Cϵ��ģ�K��ģ�K�����Ժ��`����ʹ�����ɞ�ԭ���_�l(f��)I/O�������x��
����
�����D2 ���ڌ�ԭ��ϵ�y(t��ng)�B�ӵ���������Cϵ��I/Oģ�K
�����Ñ������ڻ���USB��ϵ�y(t��ng)��ʹ��Cϵ��ģ�K�������B��NI CompactDAQ���o���O(sh��)�䣬��������NI CompactRIO�Ͱ忨��(j��)NI�ΰ�RIO��Ƕ��ʽϵ�y(t��ng)��NI�͵������S���ṩ�˳��^80��(g��)Cϵ��ģ�K�����ڌ��Ñ���ԭ��ϵ�y(t��ng)�cģ�M����(sh��)�֡��\(y��n)��(d��ng)��ͨ���Լ�Ƕ��ʽ�������cԭ��ϵ�y(t��ng)�M(j��n)�н��������⣬�Ñ�����ʹ��LabVIEW���ߌ�(du��)�����@Щƽ�_(t��i)�M(j��n)�о��̣����ṩ���c�����@ЩI/Oģ�K�M(j��n)�н������(q��)��(d��ng)����͎�(k��)��
����ʹ���_�l(f��)ʽܛ����(sh��)�F(xi��n)����IP
�����ڴ����(sh��)��r�£�Ƕ��ʽ�O(sh��)Ӌ(j��)����Ҫ�IJ�����Ƕ�����O(sh��)Ӌ(j��)�еĿ����㷨��̎���㷨��Ҳ�Q��֪�R(sh��)�a(ch��n)��(qu��n)���ڴ����(sh��)��r�£��Ñ������ѽ�(j��ng)�������ض���ʽ�_�l(f��)��IP(����ANSI C���ı���(sh��)�W(xu��)��VHDL������)����IP�D(zhu��n)�Q�鹦��ԭ��ϵ�y(t��ng)����(hu��)�Ǻ��M(f��i)�r(sh��)�g���^�̡��x��һ��(g��)�_�ŭh(hu��n)�������Ԍ��Ñ���IP�cԭ��ϵ�y(t��ng)����������������һ���@�ӿ��Ԍ�����׃��ʮ�ֺ�(ji��n)�Ρ�LabVIEW�ṩ�˸�(j��)�_��ʽ�h(hu��n)�����Ñ������Á������κάF(xi��n)���C���ı���(sh��)�W(xu��)�Լ�VHDL IP��
�������C(j��)е�����cܛ���O(sh��)Ӌ(j��)�M(j��n)������
��������(sh��)��ԭ���O(sh��)Ӌ(j��)���ĸ����nj��C(j��)е�O(sh��)Ӌ(j��)�cܛ���O(sh��)Ӌ(j��)�M(j��n)���B�ӵ����̵����g(sh��)�Z���������O(sh��)Ӌ(j��)ܛ���c�C(j��)е����������һ�������������_�l(f��)ԭ��ϵ�y(t��ng)���档ʹ�Ô�(sh��)��ԭ���O(sh��)Ӌ(j��)���Ñ����Ԅ�(chu��ng)��̓�Mԭ��ϵ�y(t��ng)�����o�蘋(g��u)���C(j��)еϵ�y(t��ng)��
����NI�cSolidWorks�M(j��n)�к��������Ñ��ṩ�ˌ��C(j��)е�����c�����O(sh��)Ӌ(j��)ܛ���M(j��n)�����ϵĹ��ܡ��@��(g��)�¹��ܱ�����LabVIEW 2009��NI SoftMotionģ�K�У��Ñ�������LabVIEW�И�(g��u)�������O(sh��)Ӌ(j��)�㷨�������ƹ����cSolidWorks�C(j��)еģ��������һ��ʹ���挍(sh��)�ęC(j��)еģ�͌�(du��)�����㷨�M(j��n)�Мy(c��)ԇ�����o�蘋(g��u)���C(j��)еϵ�y(t��ng)��
����ʹ�ð������g�����\(y��n)�М�(zh��n)���Ӳ��
������Ƕ��ʽ�O(sh��)Ӌ(j��)�е��������(zh��n)֮һ�DŽ�(chu��ng)�����{(di��o)ԇ�Լ��(y��n)�C�(q��)��(d��ng)����(j��)ܛ��������Ƕ��ʽϵ�y(t��ng)������Ӳ���M��������һ���^ȥ�������^����Ҫ�Ñ���ɣ��@��Ƕ��ʽԭ���O(sh��)Ӌ(j��)����׃�Ï�(f��)�s���Һĕr(sh��)��
����NI���g��ܛ���(q��)��(d��ng)�����˂��y(t��ng)�ΰ�Ӌ(j��)��C(j��)������Ƕ��ʽϵ�y(t��ng)�ṩ������������a(ch��n)���������Լ����Еr(sh��)�g�Ļ����(q��)��(d��ng)����ķ������(q��)��(d��ng)����ܛ�����������÷���(w��)ܛ��������ÿ��(g��)֧�ֿ��؏�(f��)����I/O(RIO)�O(sh��)���С���(n��i)�������g��ܛ���(q��)��(d��ng)���߰������¹��ܣ�
����? ��(n��i)������(sh��)�������cģ�M����(sh��)�֡��\(y��n)��(d��ng)��ͨ��I/O�Լ�FPGA�M(j��n)�н���
����? ���ͺ���(sh��)��������FPGA�c̎����֮�g�M(j��n)�Д�(sh��)��(j��)ͨ��
����? ���ڌ�FPGA/̎�����c��(n��i)��֮�g�M(j��n)�н����ķ���
����? ���ڌ�̎�����c�ⲿ�O(sh��)��(RS232���нӿڡ���̫�W(w��ng))�M(j��n)�н����ĺ���(sh��)
����? �����ܵĶྀ���(q��)��(d��ng)����
������Ҫ��ҕHMI
�����Еr(sh��)����ʾ�뷨�(ji��n)��Ҳ����õķ�����ͨ�^HMI�����Ñ����档����Ñ������ҵ����ڿ��٘�(g��u)���Ñ������ܛ�����ߣ��Ñ������c���ڵĿ͑���Ͷ�Y��һ���ڸ����O(sh��)Ӌ(j��)���̵����ڌ�(du��)�����M(j��n)�Мy(c��)ԇ��
����
�����D3 LabVIEW�D�λ����̰�����(n��i)���Ñ�����
����LabVIEW�D�λ��_�l(f��)���ߞ���ٽ����Ñ������ṩ�˶�N�x�(xi��ng)�����ȣ�ÿ��(g��)LabVIEW����(��VI)�����ˑ�(y��ng)�ó���ĈD�λ����a�ͳ�����Ñ����档��ˣ��c���������Z�Բ�ͬ���Ñ�����Ҫ�����������ӵij���(g��u)���Ñ����棬ʹ��LabVIEW���Ñ��������M(f��i)�õ��Ñ����档��LabVIEW�У��ṩ�˔�(sh��)�ق�(g��)��(n��i)���Ñ������(xi��ng)Ŀ���ĈD�����ܱPֱ�����S�DƬ�ؼ��������Ñ���ԭ��ϵ�y(t��ng)���٘�(g��u)��HMI��
�����y(c��)��ԭ��ϵ�y(t��ng)
�������O(sh��)Ӌ(j��)���̵��������ԭ���O(sh��)Ӌ(j��)����һ��(g��)��(y��u)�c(di��n)�������Ñ��ṩ�˱M���������O(sh��)Ӌ(j��)�ęC(j��)��(hu��)��Խ�����ԭ��ϵ�y(t��ng)���_�l(f��)��Ҳ�Ϳ���Խ����_ʼ�y(c��)ԇӲ���cܛ���O(sh��)Ӌ(j��)���Ķ����Խ������ӿɿ���ϵ�y(t��ng)�����S����r�£��Ñ�������Ҫ�ȵ���ɮa(ch��n)Ʒ�_�l(f��)�ŕ�(hu��)�_ʼ���]�y(c��)ԇ��ͨ�^��(du��)ԭ��ϵ�y(t��ng)�M(j��n)�Мy(c��)ԇ���Ñ����H�܉������ɿ��Įa(ch��n)Ʒ������߀���Ը�����_ʼ�O(sh��)Ӌ(j��)���a(ch��n)�y(c��)ԇϵ�y(t��ng)��
����
�����D4 ����NI�Ĝy(c��)ԇ�a(ch��n)Ʒ���ڜy(c��)ԇԭ��ϵ�y(t��ng)
�����ژ�(g��u)��ԭ��ϵ�y(t��ng)�r(sh��)�����]�܉�ʹԭ��ϵ�y(t��ng)�O(sh��)Ӌ(j��)׃�ø��Ӻ�(ji��n)�εĹ��ߡ��Ñ�������ԭ��ϵ�y(t��ng)���O(sh��)Ӌ(j��)�c�y(c��)ԇ�У�ʹ�ÈD�λ�ϵ�y(t��ng)�O(sh��)Ӌ(j��)���ߡ�LabVIEW��ģ�K���y(c��)ԇӲ��(����PC��PXI/CompactPCI���g(sh��))�܉�����ԭ��ϵ�y(t��ng)�У������Ñ�����،�(du��)�O(sh��)Ӌ(j��)�M(j��n)�Мy(c��)ԇ��
��������?g��u)��뷨�M(j��n)��F(xi��n)��(sh��)
����ԭ���_�l(f��)��Ƕ��ʽ�O(sh��)Ӌ(j��)���̵���Ҫ���֡���Ͷ�Y�ߡ��͑�������չʾ�뷨���ܵ������Ǟ��뷨�õ��A(y��)�����ѷ���֮һ��NI�D�λ�ϵ�y(t��ng)�O(sh��)Ӌ(j��)���߿����ڟo������_�l(f��)�r(sh��)�g�ʹ����O(sh��)Ӌ(j��)�F(tu��n)�(du��)����r�£����ٵ���ɾ߂书�ܵ�ԭ��ϵ�y(t��ng)���ڌ�(du��)��һ��(g��)�O(sh��)Ӌ(j��)�M(j��n)��ԭ���_�l(f��)�r(sh��)��Ո(q��ng)���]ʹ��LabVIEW�Լ�NIԭ���_�l(f��)Ӳ����ʹԭ���_�l(f��)׃�ø����ݡ�
]]>
Ŀǰ�������܉�ʹ���@Щ���¼��g(sh��)�����̎����������ò�ʹ�÷nj������о����O(sh��)Ӌ(j��)��ܛ�����ߡ������°��LabVIEW�t�������ṩ�˪�(d��)����ƽ�_(t��i)��ͨ�^���ö��̎�������g(sh��)��ߜy(c��)ԇ������ϵ�y(t��ng)�����������ڻ���FPGA�ĸ�(j��)���Ƽ�Ƕ��ʽԭ�͑�(y��ng)���пs���_�l(f��)�r(sh��)�g������ݵ�(chu��ng)���ֲ�ʽ�y(c��)��ϵ�y(t��ng)���ɼ��h(yu��n)�̔�(sh��)��(j��)��
���ęC(j��)���˼��g(sh��)����τ�(d��ng)����܇�O(sh��)Ӌ(j��)�����˝M��ǰ�ؑ�(y��ng)���е����ܼ�Ч�������Ñ���횼��r(sh��)���T����̎������FPGA���o��ͨ�ŵ����¼��g(sh��)�����Լ��đ�(y��ng)�ã��� NI��˾���á�CEO�愓(chu��ng)ʼ��֮һJames Truchard��ʿ��ʾ����LabVIEWͨ�^���о��̞��������g(sh��)�đ�(y��ng)���ṩ�˽ݏ���ͬ�r(sh��)��Ҳ���Ñ��ṩ�����`���ԁ�ᘌ�(du��)���N��(y��ng)���I(l��ng)���O(sh��)Ӌ(j��)�(y��u)���Ľ�Q��������
��(d��ng)��(bi��o)��(zh��n)ϵ�y(t��ng)Խ��Խڅ���������(g��)̎���ˣ��y(c��)ԇ�y(c��)��ϵ�y(t��ng)��(sh��)�F(xi��n)��������������Ŀ�����Ҳ��Խ��LabVIEWƽ�_(t��i)�U(ku��)չ�˃�(n��i)Ƕ�Ķྀ�̼��g(sh��)�����°�ܛ����ͨ�^��˃�(y��u)�������ṩ����(j��)Ӌ(j��)�����ܣ��������̎�̎�����������Ĝy(c��)����(sh��)��(j��)���M���(j��)���Ƒ�(y��ng)�õ�Ҫ����ߜy(c��)ԇϵ�y(t��ng)����������
�����������ܣ�LabVIEW 8.6�����˳��^1,200��(g��)����(y��u)���ĸ�(j��)��������(sh��)���ڶ��ϵ�y(t��ng)�Ŀ��Ɯy(c��)ԇ��(y��ng)�����ṩ�����١�����(qi��ng)��Ĕ�(sh��)�W(xu��)����̖(h��o)̎�����ܡ�ҕ�X��(y��ng)��ͬ���Ķ��ϵ�y(t��ng)�Ы@�棬NIҕ�X�_�l(f��)ģ�K�Є�(chu��ng)���ԵĈD��̎������(sh��)���܉��Ԅ�(d��ng)�ڶ���g���䔵(sh��)��(j��)������ȫ�µĶ�������£��y(c��)ԇ���̎�ͨ�^�°�LabVIEW���{(di��o)�ƹ��߰��_�l(f��)�y(c��)ԇ�o���O(sh��)��đ�(y��ng)�ã���Ч�ʿ����4��֮�ࣻ����ϵ�y(t��ng)���̎�ͨ�^LabVIEW 8.6 �����O(sh��)Ӌ(j��)������ģ�K��(sh��)�F(xi��n)����ģ�ͷ��棬Ч�ʿ��@�����5��֮�ࡣ���⣬ʹ��LabVIEW��D�Ԅ�(d��ng)���ֹ��ܣ����̎����܉����ݵ��R(sh��)�e���a�IJ��в��֡�
������LabVIEWֱ�^�Ĕ�(sh��)��(j��)��ģʽ�����̎�������ͨ�^ʹ��LabVIEW FPGAģ�K������FPGA�ĬF(xi��n)�ɼ��õ��̘I(y��)Ӳ������NI CompactRIO�����Զ��x�y(c��)��������ϵ�y(t��ng)��(y��ng)�ã���댧(d��o)�w�(y��n)�C����(j��)�C(j��)�����ƣ��Ķ���(sh��)�F(xi��n)���ѵ����ܡ�LabVIEW 8.6һ������،�FPGA���g(sh��)���o�����]�Ќ��I(y��)��Ӳ�������Z�Ի�弉(j��)�·�O(sh��)Ӌ(j��)��(j��ng)�(y��n)�Ĺ��̎�����
LabVIEW 8.6�M(j��n)һ���s����FPGA���_�l(f��)�r(sh��)�g�������������S���̎���ֱ�ӌ�(du��)CompactRIO�ɾ����Ԅ�(d��ng)������ (PAC) �M(j��n)�о��̣����o횷քe��(du��)FPGA���̡����⣬ȫ�·��湦���܉�����X���(y��n)�CFPGA��(y��ng)�ã��Ķ����s�����ھ��g�����ĵ��_�l(f��)�r(sh��)�g��LabVIEW 8.6߀�ṩ��ȫ��IP�_�l(f��)���������ԣ�����ȫ�¿��ٸ����~׃�Q(FFT) IP�ˣ���(sh��)�F(xi��n)�l�V�����ȹ��ܣ���C(j��)����B(t��i)�O(ji��n)�ؼ�RF�y(c��)ԇ��(y��ng)���ṩ�˸���(qi��ng)�����ܣ�ȫ�µ�������(j��)IP(CLIP)��(ji��)�c(di��n)���ɱ�ݵ،����л��������IP��(d��o)��LabVIEW FPGA������LabVIEWƽ�_(t��i)���_���ԡ�
�S���o�����g(sh��)�İl(f��)չ�����̎����ѽ�(j��ng)���Ԍ�(sh��)�F(xi��n)���y(c��)���ȑ�(y��ng)�á�LabVIEW 8.6�c�o�����g(sh��)����ϣ��܌���(sh��)��(j��)�ɼ���(y��ng)�ÔU(ku��)չ���µ��I(l��ng)���У���h(hu��n)���������O(ji��n)�y(c��)�ȡ�LabVIEW�D�λ����̵��`���Լ��o̎���ڵ�Wi-Fi�W(w��ng)�j(lu��)��(g��u)���܌��o���B������ȫ�»����еĻ���PC�Ĝy(c��)��������ϵ�y(t��ng)�С�
�����o����(sh��)��(j��)�ɼ��O(sh��)�估���^20�ҵ������o���������(q��)��(d��ng)��֧���£�LabVIEW 8.6���骚(d��)����ܛ��ƽ�_(t��i)����(ji��n)���˷ֲ�ʽ�y(c��)��ϵ�y(t��ng)�ľ����^�̡���LabVIEW 8.6�У��o�������a�ļ��ɱ�ݵ�ͨ�^NI Wi-Fi ��(sh��)��(j��)�ɼ� (DAQ) Ӳ�������Ô�(sh��)��(j��)�ɼ���(y��ng)�á�ͬ�r(sh��)��LabVIEW 8.6��ȫ�µ�3-D��ҕ�������܉��h(yu��n)�̜y(c��)���c�O(sh��)Ӌ(j��)ģ�ͣ������O(sh��)Ӌ(j��)�(y��n)�C������(g��)�^�̡�
��(d��ng)�����ˆT��ϵ�y(t��ng)�g���m(x��)���B���c�L��Խ��Խ�ձ�r(sh��)�����̎�ϣ����������һλ�ö���ͨ�^�W(w��ng)�j(lu��)���cϵ�y(t��ng)�M(j��n)�н�����LabVIEW 8.6���S��LabVIEW��(y��ng)���D(zhu��n)������X�͌�(sh��)�r(sh��)Ӳ���ϵľW(w��ng)�j(lu��)����(w��)����Web Service�����Ķ������κξW(w��ng)�j(lu��)�(q��)��(d��ng)���O(sh��)�����B�ӣ��������֙C(j��)��PC�C(j��)�ȡ�ͨ�^�@һ���ԣ����̎��܉���Ø�(bi��o)��(zh��n)�W(w��ng)�j(lu��)���g(sh��)
]]>�����o���{�ϵ�y(t��ng)���ṩ�����İ�ȫ���ܣ������Ӽt�⣨IR�����C(j��)������^���������������M(j��n)���O(sh��)Ӌ(j��)߀�����÷����V���Ă����������ѝ��ڵ�Σ�U(xi��n)��r���Ķ�ʹ܇�v�����R(sh��)���܇��Ľ�ͨ��r��܇���������Լ����ܵ���ײĿ��(bi��o)����K��Ŀ��(bi��o)��܇�v�܉��Ԅ�(d��ng)��(du��)�@�N��Ϣ��������(y��ng)����˾�C(j��)�ṩ��Ϣ�Լ�������r�µ�܇�v�����������Ķ��ɱ��C�˿͵İ�ȫ�����磬��Щ���µĿ�܇�а��b��ҕ�l�z��C(j��)���O(ji��n)ҕǰ��ĵ�·��r�����܇�v�ڛ]��ʹ��ָʾ������r�¸�׃���·�����������������˾�C(j��)̫ƣ���ˣ���ôϵ�y(t��ng)�͕�(hu��)ͨ�^܇��(n��i)�ēP(y��ng)���o�����澯��
����ͨ�^�����������{��(d��ng)�����o���{�߀���ṩ���ߵ����mˮƽ�����磬���y(t��ng)��Ѳ���������S˾�C(j��)�O(sh��)��һ��(g��)�̶�������ٶȣ�ͬ�r(sh��)����Ҫ�r(sh��)���ք�(d��ng)���ơ����F(xi��n)�ڵ���܇�t�ṩ�Ԅ�(d��ng)Ѳ�����ƣ�ACC�����ܣ������Ԅ�(d��ng)�������T�̈́x܇���m��(y��ng)ǰ��܇�v���ٶȣ��Ķ��c�䱣�ְ�ȫ���x�����ǰ���܇�v�����_���׃���·����ACC��(hu��)�Ԅ�(d��ng)�����y(t��ng)Ѳ�����Ƶ��A(y��)�O(sh��)�ٶȡ�
�����o���{�ϵ�y(t��ng)߀��ϣ���������^�ġ���Ӡ����b�á�����߽�ͨЧ�ʡ����磬܇�(du��)���I(l��ng)�^��܇��˾�C(j��)�ք�(d��ng)�{�����S�Ŀ�܇�t�Ԅ�(d��ng)�{���˜p�p˾�C(j��)���S��ؓ(f��)��(d��n)���⣬��܇�g�ľ��xҲ�ɴ��s�̣���?y��n)����푑?y��ng)�ٶȸ���Ѹ�١��@�Ӳ��H�ɹ�(ji��)�s�����ĵ�·��e���g����������ǰ��܇�v�ĺ��������Ӱ푣�߀Ҫ��(ji��)�sȼ�ϡ�
������һ�N���d�İ�ȫ���g(sh��)�Q�顰����(d��ng)ʽ�ˆT�R(sh��)�eϵ�y(t��ng)��������(gu��)����Ҫ���2006���_ʼ�������¿���܇������܉����(j��)�ˆT���w�́����_���ҡ����ϵ�y(t��ng)ʹ�ñ��o(h��)�����܉����ܡ����_���տs���@�N���ڳˆT�w�ص�ϵ�y(t��ng)���Ɏ�����܇�����̝M����������ġ�����(gu��)(li��n)��܇�v��(bi��o)��(zh��n)��ȫ��Ҏ(gu��)��FMVSS-208��Ҫ��ԓ��Ҏ(gu��)Ҫ����ұ���܉�ᘌ�(du��)��ͬ�ˆT���w�ظ�����Ч�ش��_����2004���_ʼ��ÿ����܇������������(gu��)�N�۵�܇�v����35%����b�����M(j��n)�Ě���ϵ�y(t��ng)���@һ��(sh��)����2006 �ꌢ��ߵ��ӽ�100%���^�麆(ji��n)�ε�ϵ�y(t��ng)���ð��b�ڳˆT���|�µ��w���������g(sh��)�팍(sh��)�F(xi��n)����(j��)�ˆT�R(sh��)�e�㷨�Ϳ�����̖(h��o)̎��ʹ��܇�����������ɸ���(j��)��ͬ����r�����_���տs�ˆT���ң��Ķ��ɴ����߳ˆT��ȫ�Բ����������ɱ��������(j��)��ϵ�y(t��ng)�t���ð��b��܇��(n��i)�����C(j��)��z�y(c��)���R(sh��)�e�ˆT��ͬ�r(sh��)���㷨�Ͽ��]���ˆT�{(di��o)ԇ���x���ҵľ��x���Д��¹ʰl(f��)���r(sh��)���Ҵ��_�ĕr(sh��)�g���ٶȺͳ̶ȡ�
����Xilinx FPGA���o���{�ϵ�y(t��ng)�е���(y��ng)��
�����D2�o����ِ�`˼�F(xi��n)��(ch��ng)�ɾ����T��У�FPGA����(y��ng)����ACC�o���{�ϵ�y(t��ng)��һ��(g��)�����Կ�D��
����ϵ�y(t��ng)���֞鳬����ݔ��̎��������(du��)���ٵĂ�����ݔ���ݔ��������Ϣ��ÿ��(g��)���ֶ�������(y��ng)̎���������磬һ��(g��)Xilinx MicroBlaze 32Ƕ��ʽܛ��(n��i)��̎��������Virtex-II Pro FPGA��Ƕ���IBM PowerPC���Ŀ���֮�¡����ٲ������ڌ�(du��)���b��܇�vǰ���ҕ�l�z����Ϣ�M(j��n)�Ќ�(sh��)�r(sh��)̎�������ڑ�(y��ng)�ã�����ײ���o��̎���澯�����������c(di��n)����(sh��)�r(sh��)̎���^��(du��)�Ƿdz��P(gu��n)�I�ġ�ͨ����Ҫ�ɂ�(g��)��������C(j��)���@�����w�D�����@�ӾͿ�����FPGA��Ӌ(j��)����D�����ȣ�ֱ���cǰ�����w�Č�(sh��)�H���x���P(gu��n)�����Y(ji��)�����_(d��)�ͼ���y(c��)�����Լ��������݃x��܇݆���������\(y��n)��(d��ng)�z�y(c��)��Ϣ�������ஔ(d��ng)��(zh��n)�_��Ӌ(j��)���܇�v�܇�����r�����·����������ȫ�`���FPGA�������Ʒҕ�l�M�����O(sh��)�������̿������_�l(f��)���^(q��)�e�ڸ�(j��ng)��(zh��ng)�S��ϵ�y(t��ng)���ܵġ���(d��)�صġ���(y��u)����߅���z�y(c��)���D����Ⱥ�����(qi��ng)�㷨����(sh��)�r(sh��)����̎���@Щ��Ϣ��Ҫʹ��Ӌ(j��)���ܼ��Ĕ�(sh��)����̖(h��o)̎����DSP���㷨��Ȼ����ܛ��̎��o���M������Ҫ�M�܂��y(t��ng)DSP̎����Ҳ��һ�N�x��ͨ����Ҫ��Ƭ�������������˸��ٵ��΄�(w��)������ASSPҕ�l̎����Ҳ�o���c Xilinx FPGA��Ҳ�Q��XtremeDSP̎�����ĘO����DSP������ȡ���ҕ�l̎�����ԺQ�ߘ�C(j��)�ƿ��Ԅ��֞�ᘌ�(du��)�o���㷨����o���ķ���ײ�^�̣���Ӳ�����֣��Լ��������·��ƫ��ȵ����澯��̎����ܛ�����֡����ٶ��P(gu��n)�I��̎���^�̄��ֵ�FPGAӲ����߀���Ԍ�(du��)��(sh��)�r(sh��)�ٶ��M(j��n)�Мy(c��)ԇ�����@��(du��)��ܛ���Dz����ܵġ�
����XtremeDSP ��(sh��)�r(sh��)�D��̎��
��ô��ʲôXilinx FPGA�܉��ṩ�Ȃ��y(t��ng)DSP�����ҕ�l̎�������أ��������ԭ��������FPGA�Y(ji��)��(g��u)�܉�?q��)��F(xi��n)��(sh��)��(j��)�IJ���̎��������Xilinx������Vir tex- Proϵ������߀������Ƕ��ʽ�������˷���ģ�K��У������M(j��n)һ����߈D��̎�����������c������(du��)�ȣ�DSP̎��������(zh��)��ָ��͔�(sh��)��(j��)��������������ʽ̎�����������FPGA�����Þ��܉��Ј�(zh��)�ж���(g��)�������چ�(g��)�r(sh��)����ڃ�(n��i)���ij˷��ۼӣ�MAC����Ԫ��У�����������y(t��ng)��DSP���ǘ���Ҫ����(g��)�r(sh��)����ڲ�����һ��(g��)������MAC��Ԫ�Ј�(zh��)���ꮅ��
����Xilinx FPGA߀���п����Ü�(zh��n)�_��MAC��Ё�M��Ӌ(j��)��Ҫ����~�⃞(y��u)�c(di��n)���@Щ���Ԍ�(du��)����ɈD��Ӌ(j��)��dz����롣�@�ӾͿɌ�(du��)�D���еĶ���(g��)���شأ����xɢ����׃�Q��DCT���ĺ�K���M(j��n)�в���Ӌ(j��)�㣬�����������������(g��)�D��FPGA���ܵ����߀���������~���̎�����磬���_����ֵ����Ҫ�Ĵ惦(ch��)����(sh��)���ɸ�С����?y��n)�F(xi��n)�ڿɌ�(sh��)�r(sh��)̎����
�������ˌ�(sh��)�r(sh��)�������⣬Xilinx FPGA�Ŀ��ؾ�������߀�ṩ�˃�(y��u)����ϵ�y(t��ng)�`���ԣ�֧���㷨����(j��)����ʹ�ڲ����Ժ��@һ�c(di��n)�dz���Ҫ����?y��n)�Ŀǰ���o���{�ϵ�y(t��ng)��Ȼ̎�������аl(f��)�A�Ρ��S��߅�غ�Ŀ��(bi��o)�z�y(c��)�㷨�IJ�����M(j��n)�����ڔ�(sh��)����Ѓ�(n��i)���Ӳ������(j��)�����Ҳ���Ҫ�����O(sh��)Ӌ(j��)�·�塣
�������ÿɾ������O(sh��)�����܇�W(w��ng)�j(lu��)
�����S����܇���ݻ�������С�;W(w��ng)�j(lu��)���O(sh��)�������̱�횴_���ڱ���ľW(w��ng)�j(lu��)�f(xi��)�h���ķN��(bi��o)��(zh��n)������ɹ��ģ�������Щ��(bi��o)��(zh��n)�܉�?y��n)��Լ��������ĺ�̎����ͬ�ľW(w��ng)�j(lu��)���g(sh��)���Á�M����܇�еIJ�ͬ��Ҫ�����{�œ��(n��i)�Ķ�ý�w�����������ý�w��ϵ�y(t��ng)��ݔ��MOST��ֱ����܇���ƾW(w��ng)�j(lu��)����FlexRay�����D2���x����һ�N�A(y��)�(y��n)�C�Ŀ��ƅ^(q��)��W(w��ng)�j(lu��)��CAN���ӿ���(n��i)���������ӡ�
�����ɑ�(y��ng)����܇��(n��i)��һ�N������d�W(w��ng)�j(lu��)�f(xi��)�h�����{(l��n)�����{(l��n)���o�����g(sh��)��һ�N�����Ƅ�(d��ng)�O(sh��)���WAN/LAN�����c(di��n)�ĵͳɱ����������Ķ̾��x���l���g(sh��)���@�NԴ��Ӌ(j��)�������ИI(y��)�Ę�(bi��o)��(zh��n)�������֙C(j��)��Ӌ(j��)��C(j��)��PDA���O(sh��)��֮�g�������һ�N�̾��x�o���B�ӌ�(sh��)�F(xi��n)����Ļ��B��
�������磬�{�T���������{(l��n)���o�K���C(j��)�c�ڴ��е��֙C(j��)ͨ������˿ɱ���˾�C(j��)���IJ�����˰�ȫ�ԡ���܇���I(y��)������һ��(g��)�����dȤ�M��SIG�������x�{(l��n)����܇��(bi��o)��(zh��n)��ԓ�����dȤ�M�ijɆT������܇��ý�w�ӿڅf(xi��)���M��(AMIC)�����R����ķ��-���R˹�ա����ء�ͨ����܇���S����܇�Լ�����܇����˾�ȡ��{(l��n)������܇�Б�(y��ng)�õ�һ��(g��)����Johnson Controls��˾�������֙C(j��)ϵ�y(t��ng)��BlueConnect����ԓϵ�y(t��ng)���S˾�C(j��)���p�ַ�ס����P����r��ͨ�^֧���{(l��n)�����ܵ��֙C(j��)����(li��n)ϵ��
����Ȼ�����{(l��n)���������L(zh��ng)��֧��߀���چ��}��ͬ�r(sh��)܇��(n��i)�h(hu��n)������(du��)���{(l��n)���O(sh��)�乤����Ӱ�Ҳ��Ҫ�J(r��n)�濼�]���I܇������܇�v�ĉ���Ҫ�����M(f��i)a(ch��n)Ʒ���֙C(j��)�L(zh��ng)�ö࣬���оƬ�����̱�횽�Q�ɴ˶�������֧�ֺͷ���(w��)�����ڲ�ƥ��Ć��}��Ȼ��������ڵ������e�k��Convergence 2002չ��(hu��)�ϣ����R˹�ռ��F(tu��n)չ���ˑ�(y��ng)�����{(l��n)�����g(sh��)����܇��
�����c����ASSP��ȣ�����FPGA������֮̎һ�����S���̎��O(sh��)Ӌ(j��)�����_ƥ��ϵ�y(t��ng)Ҫ��Ľӿں����O(sh��)�����_�l(f��)�������A��ԇ�D�B�ӵ���ͬ����܇�W(w��ng)�j(lu��)�r(sh��)���@һ�c(di��n)�e���á���(d��ng)ԇ�D���ٌ��a(ch��n)Ʒ�����Ј�(ch��ng)�r(sh��)��оƬ�M��ASIC�����O(sh��)Ӌ(j��)���ɱ����F�ֺ��M(f��i)�r(sh��)�g���ژ�(bi��o)��(zh��n)��(sh��)�F(xi��n)�����ڣ�����W(w��ng)�j(lu��)�f(xi��)�hҎ(gu��)������׃��������֧�����µİ汾����ʹ��FPGA���O(sh��)Ӌ(j��)�r(sh��)ֻ��Ҫ��(ji��n)�ε���ܛ����Ȼ�����������dFPGAӲ�����þͿ����ˡ�����߀Ҫ������Xilinx IRL�����ؾW(w��ng)��������߉��ͨ�^�V��W(w��ng)������@һ�c(di��n)����˲���Ҫ�ɱ��߰����ɹ��M(f��i)�û��~��������Ϳ���ͨ�^�h(yu��n)�̾S�o(h��)���Ӳ���ġ�
����ᘌ�(du��)��܇��(y��ng)�õ�Xilinx IQ��Q����
������M����܇����O(sh��)���O(sh��)Ӌ(j��)�ˆT����Ҫ��ِ�`˼��Xilinx����˾�Ƴ���һϵ��֧��?j��n)Uչ���I(y��)�ضȷ��������������Q�顰IQ���������@Щ����������Xilinx Ŀǰ���ϔU(ku��)չ�ضȼ�(j��)��Q��Ҫ��ĬF(xi��n)�й��I(y��)��(j��)��I��FPGA��CPLD����1���������µ�IQ�ضȷ���Ҫ��ĵ�һ���������ܶȷ�����5K�T��3K�T�� Spartan-XL 3.3V FPGA���Լ�36��72���Ԫ��XC9500XL 3.3V CPLD����δ���Ďׂ�(g��)�r(sh��)�g�IQ�ضȷ�����������(hu��)�U(ku��)չ�����ܶȸ��_(d��)30�f�T��FPGA�������Լ��ܶȸ��_(d��)512��(g��)���Ԫ��CPLD���������2��ʾ��
�����Y(ji��)Փ
�����o���{�ϵ�y(t��ng)���_�l(f��)�͑�(y��ng)����Ҫ�����܈D��̎����ͬ�r(sh��)�ֲ�ϣ��������Ŀ��(bi��o)�z�y(c��)����܇�W(w��ng)�j(lu��)���g(sh��)�аl(f��)�������A������Ҫ���`���ԡ�����Xilinx FPGA������ϵ�y(t��ng)�ĺ��Ğ�I(y��)���ṩ����ѵ�DSP���ܺ͟o�c���ȵľW(w��ng)�j(lu��)�B�Ә�(bi��o)��(zh��n)֧��������ͬ�r(sh��)��ϵ�y(t��ng)�O(sh��)Ӌ(j��)���ṩ��һ��(g��)��ȫ�`����O(sh��)Ӌ(j��)ƽ�_(t��i)��ͨ�^�Ɍ�(sh��)�r(sh��)�����Ĵ��ϵ�y(t��ng)�����{�?c��)ˆT�ṩ�o���{�澯���o��܇�v���ƹ��ܾͳɞ���ܣ��Ķ��ɴ�����܇�v�{�ͳ����İ�ȫ��]]>
�������ڡ��Ƽ����˞鱾 - CES�Y(ji��)�Z��һ�����v�ģ��Ƽ��ڽ�20����l(f��)���˷��츲�ص�׃����������Ƅ�(d��ng)��Ҫ�����ڰ댧(d��o)�w���g(sh��)���w�ٰl(f��)չ���������ĸ�������ŵ��˂�ͨ�^ģ��(sh��)׃�Q������Ȼ���һ��ģ�M��׃�Q����(sh��)�����ڔ�(sh��)���������҂�5ǧ������͵Ĺ��� - ��(sh��)�W(xu��)��������̎��ģ�M�����磬�ڔ�(sh��)��߉�Ļ��A(ch��)���˂��ְl(f��)���˻���ָ���Ӌ(j��)�㡢��(sh��)����̖(h��o)̎���ȼ��g(sh��)�����������҂�����ĉ��sҕ�l����(sh��)��ͨ�š��o���W(w��ng)�j(lu��)����(li��n)�W(w��ng)�ȵȣ������f����(sh��)�֡��Ǯ�(d��ng)��댧(d��o)�w�Ƽ��������ɣ��҂���̎��һ��(g��)����(sh��)�֕r(sh��)���������籾��ȵ�CESҲ�������ɶ��x���ˡ���(sh��)�ֽ�(j��ng)��(j��)����������Ӽ��g(sh��)��ͬ�ʂ���֪������(sh��)��߉�Ļ�����Ԫ���ǡ��T�����ɱ���ġ��T����(g��u)�ɸ�ʽ���ӟoՓ��ô��(f��)�s��߉���ܡ�FPGA - ���F(xi��n)��(ch��ng)�ɾ��̡����T��С���Ҳ�ͳ��˔�(sh��)���I(l��ng)��ġ����ߡ�,�������Դ���������Ʒ��
FPGA�����M(j��n)
���ȁ����һ�vʷ��1989���ҵ�һ�ν��|���·��ĕr(sh��)�������ܲ���һϵ�е�TTL��CMOSоƬ��һ�w14��20ֻ���_��оƬ��һ��ֻ��4-6��(g��)��(ji��n)�εġ��T����ʮ�ׂ�(g��)оƬ�Ĵ����Ҳ����Ɍ�ַ���g�a֮Ĺ��ܣ�ʹ�������Ƿdz���ʹ�࣬���Ҫ��߉��ֻ�������g(sh��)���и��·�岢�M(j��n)���w����94��ĕr(sh��)�����_ʼʹ��GAL
��ǰ��ʮ���ĕr(sh��)�g��ɾ���߉����������FPGA�ĽY(ji��)��(g��u)���������ٶȡ�����ܛ��������(w��)ģʽ�ȷ��涼���˾��׃����С��������Ĕ�(sh��)��߉����(f��)�s��ͨ�žW(w��ng)�j(lu��)��ҕ�l����aϵ�y(t��ng)����ASICԭ���O(sh��)Ӌ(j��)���o̎��ҊFPGA����Ӱ���������һ��(g��)�аl(f��)�õ��·���ϛ]��FPGA���@��(g��)�аl(f��)�(xi��ng)Ŀ�ļ��g(sh��)�����������ߣ����һ��(g��)���̎�����(hu��)ʹ��FPGA��������������˼���e���f�Լ�����Ӳ���ģ����һ��(g��)������ԺУ߀�]��FPGA���n�̣��@��(g��)�W(xu��)Уһ��ʮ�ֲ����V����ҪXilinx��W(xu��)Ӌ(j��)���Ď�����
FPGA�ă�(y��u)��(sh��):
����(j��)��(y��ng)�õIJ�ͬ���O(sh��)Ӌ(j��)�������õĽ�Q����Ҳ��(hu��)��ͬ���ڴ�Ҏ(gu��)ģ��(sh��)��оƬ�б��^���͵ļ��g(sh��)��Ҫ��:̎������DSP�����ü����·ASIC�ȣ�����(du��)���@Щ���g(sh��)�đ�(y��ng)�Á��v��F(xi��n)PGA��ʲô��(y��u)��(sh��)��?
1. ̎�����������̎����(����������)Ʒ�N���࣬�Y(ji��)��(g��u)Ҳ������ͬ����4λ��8λ��16λ��32λ��64λ����8051��PIC��RISC��ARM��MIPS��Xtensa�Լ�X86�ȣ�����������S���Ľӿ�ͬ���N���O(sh��)�M(j��n)���B�ӣ�ͨ�^ܛ����(zh��)�в�ͬ���M(j��n)�̣��Ķ����һ�����΄�(w��)���������������Y(ji��)���M(j��n)��ݔ���������fͨ�^ܛ������̎�����������κ����飬����������ȱ�c(di��n)�����ٶ����ޣ����ⲿ�r(sh��)犵Ĺ�(ji��)��������(zh��)��һ�l�l��ָ����ܲ���̎�������̎�����S��ֻ���������оƬ���ٶ�(����Intel��оƬ�r(sh��)���2GHz���ϣ�ARM�ѽ�(j��ng)��600MHz����)����(du��)�ڸ���(f��)�s���΄�(w��)ֻ�ܶ�Ŏׂ�(g��)�ֵ�������һ��ɻҲ���ǽ���Ķ�˼��g(sh��)������һ������(f��)�sһЩ��ϵ�y(t��ng)����(hu��)�õ�̎��������ݔ��ݔ�������M(j��n)��̎���Լ��W(w��ng)�j(lu��)ͨ�ŵȣ��ܶ��M��һ�����������ͨ��̎�����ɱ��^�ͣ���˱��V�����á��F(xi��n)��̎�����I(l��ng)������T�ļ��g(sh��)�g(sh��)�Z�o�ɾ��� ��Ƕ��ʽϵ�y(t��ng)���ˣ����ҿ���ؓ(f��)؟(z��)�ε��v�������(sh��)�ˌ�(du��)��Ƕ��ʽϵ�y(t��ng)����������Ƭ���������e(cu��)�`�ġ���Щ��˾�����̘I(y��)�����Ƕ��ʽϵ�y(t��ng)�ԡ��ʵ۵����b��ģʽ�M(j��n)�д�Ҏ(gu��)ģ�غ��ƣ���(d��o)���˂����ѡ�Ƕ��ʽϵ�y(t��ng)��ͬijһ�NIP��ͮ����˵�̖(h��o)���@��(g��)�ИI(y��)ӿ�F(xi��n)���˴����ĸ�������Ƕ��ʽϵ�y(t��ng)��Ƕ��ʽϵ�y(t��ng)���̎���
2. DSP
3. ASIC
4. FPGA: �����^���@��ȱ�c(di��n)��������(du��)���v�ɱ��^�ߣ���Ҫ�����аl(f��)�^���л����Ј�(ch��ng)������(hu��)�ܴ�F(xi��n)PGA��ϵ�y(t��ng)�����w�r(ji��)���в����С�һ�wFPGAоƬ�ăr(ji��)��ĵ���1��Ԫ����ǧ��Ԫ���ȣ���(d��ng)Ȼ�@�ǿ�������ģ������`�����ǿ��߶ȵ����������ġ����ĺ�̎�������κ�һ�N���g(sh��)�o���ȔM�� - �����������κ����飬��������������(g��)̎������������(g��u)���Լ��ijˡ�������Ԫ�����ׂ�(g��)DSP���������@Щ̎������DSP����ͬ�r(sh��)�ɻ���й������c��ͬ�r(sh��)��߀��������оƬ��(n��i)��δ�õ��YԴ���ܶ��o���Ĺ��ܣ������f�Ǹ߶ȵ��`�
��һ��(g��)��(y��ng)�Þ������������܇���Ҳ�����˞鱾��ԓ�I(l��ng)���һ��(g��)��Ҫ�ļ��g(sh��)���c(di��n)���ǡ�˾�C(j��)����(DA)��ϵ�y(t��ng)�����ɳ������_(d��)�������C(j��)�Լ�����ȶ�N��ͬ�Ă�������(g��u)�ɣ��@Щ��ͬ�Ă������ڲ�ͬ�ĕr(sh��)�̻���ͬһ�r(sh��)�̰�����(y��ng)����̖(h��o)�ɼ������l(f��)������̎���Ԫ�M(j��n)���R(sh��)�e���\(y��n)�㡢�����Д࣬����˾�C(j��)�ڵ�܇����������Լ�ҹ�g���ĕr(sh��)���܉�?q��)��܇��ĭh(hu��n)������̵ĕr(sh��)�g��(n��i)������(zh��n)�_���Дಢ����һϵ�еİ�ȫ���o(h��)��(d��ng)�����������̎������DSP��(du��)������������̖(h��o)�M(j��n)��̎���������o�����Ј�(zh��)�ж���(g��)�΄�(w��)������ͬ����ϵ�y(t��ng)�M(j��n)�л�(li��n)����˾͕�(hu��)���ϵ�y(t��ng)��̎��r(sh��)�g���t���ɿ��Բ�Ķ���(d��o)���¹ʟo�����r(sh��)���⡣�������ASIC�أ��S���Ñ�(du��)����Ҫ��IJ������ӣ���(du��)����Ҫ��IJ�������(j��)��Ҳ��Ҫ���㷨Ҫ����ĸ��M(j��n)���@Ȼ����ASIC�oՓ���`����߀�dzɱ��϶��Dz�����ġ��D1��Xilinx������܇����_�l(f��)�ṩ�Ĺ���ģ�K���D2����һ�wSpartan-3E FPGA��ᘌ�(du��)��˾�C(j��)�����������˺ܶ�Ĺ��� ��
�D1 FPGAƽ�_(t��i)�܉�֧�ֵġ�˾�C(j��)������ϵ�y(t��ng)����
�D2 ����Xilinx Spartan-3E�ġ�˾�C(j��)��������Q����
FPGA���O(sh��)Ӌ(j��)��
FPGA�Ĺ���Խ�Ǐ�(qi��ng)��(du��)�O(sh��)Ӌ(j��)��Ҫ��Ҳ��Խ�ߣ���������ô��Ĺ��_��Ҫ������оƬ�B������������ô��Ĺ���Ҫһ��һ�еز���߉���������h(yu��n)�h(yu��n)����ʮ��ǰ̎���T��(j��)�·�ĕr(sh��)���ˡ��mȻ��������(sh��)���^FPGA�Ĺ��̎��ѽ�(j��ng)��(du��)�@��(g��)ʹ����^�������w��(hu��)����߀�ǰ��������e�ڴˣ�
1. �·���O(sh��)Ӌ(j��):
�F(xi��n)�ڵ��·���O(sh��)Ӌ(j��)��(d��ng)����(d��ng)����4�Ӱ塢6�Ӱ����������ӣ�оƬ�ķ��bҲ׃��ϡ��Ź֣�ʲôQFN��BGA�ȵȣ�����l(f��)�F(xi��n)���B�Ӳ���(du��)���ֹ��ģ��������F���Ҳ���������C�������]��¶�����Ĺ��_��������FPGAоƬ�� 256��(g��)���_��BGA���b����������ˣ����������һЩ���ܣ������ٴ�һЩ��һ������͵�1000����(g��)���_ȥ�ˣ�����ԭ��D�еķ�̖(h��o)��Ҫ���v�����죬����߀Ҫ�����Ŵ��R����ؙz�飬��t�������·��O�п����ǏU�ġ��@߀���㣬���㲼�֡������ĕr(sh��)�����(hu��)�l(f��)�F(xi��n)�ܶ�ľ�����Ť���ģ�һ���y��������늚�����Ҳ���ã�����FPGA�Ĺ��_�ǿ����������õģ���һ�¹��_�Ķ��x�Ϳ���оƬ֮�g��(li��n)�����^�����(y��u)��
��(d��ng)Ȼϵ�y(t��ng)���ٶȸ��ˣ���(du��)���ٔ�(sh��)���O(sh��)Ӌ(j��)�����֪�R(sh��)Ҫ����DZ�횵��ˣ��@������һ��(g��)�~�С���̖(h��o)�����ԡ����Ў�λ����(gu��)��ţ���@��������о��������в����������������g�������ˡ��������������Ⲣ�܉��`�(y��ng)�ã��úûؠtȥ�W(xu��)����(sh��)늴ň�(ch��ng)��Փ������늴���Փ���Ͳ��������ø��ٔ�(sh��)���O(sh��)Ӌ(j��)��FPGA֧�ָ��N���ٴ������п������ںܶ�ϵ�y(t��ng)��Ҫ���ٵĔ�(sh��)��(j��)���r(sh��)��M(j��n)���B�ӣ������̖(h��o)����o��ò������ˣ�����(g��)ϵ�y(t��ng)���ܕ�(hu��)����������ɻ
һ���ϵ�y(t��ng)����(hu��)��һ��(g��)��Ҫ�������Core늉�(1.2V��1.8V�ȣ�ȡ�Q�ڹ�ˇ)��һ��(g��)��ҪС����Ľӿ�늉�(һ����+3.3V)�������ж�M��ͬ�ĵء������@Щ��(du��)���̎��IJ����������(zh��n)֮�⣬߀�����ҕ��һ��(g��)���־����i��h(hu��n)(PLL/DLL)���@��(g��)���ֵIJ������ஔ(d��ng)?sh��)��P(gu��n)�I��һ���І��}������(g��)ϵ�y(t��ng)�����ܾ͕�(hu��)����ۿۣ��mȻ��(sh��)�ֵ��·����0����1���������ܲ����ˡ�
2 ߉�O(sh��)Ӌ(j��)��
�����PLD/FPGA�ĕr(sh��)��߀���Dz��ÈD��ݔ�뷨��ֱ�^��ԭʼ���F(xi��n)��FPGA���Ñ��������ڲ��ø���(j��)���Z�� - VHDL��Verilog���@�N�Z�Ը�(j��)����ͬC���������dz����ס�������ǧ�f���ܰ�����(d��ng)C��ʹ��������Ӳ����ܛ��߀�Dz�ͬ�ġ�4��ǰ������Ӳ�����̎��ĕr(sh��)��һ��(g��)�Ì�DSPܛ�����ֵ܌���һ��FPGA�Ĵ��a������������һ퓵�ƪ����(sh��)�F(xi��n)��һ��(g��)��Ӳ����˼·ֻҪ4��Ԓ�Ϳ�����ɵĹ��ܣ�����ҿ�Ц���á����@����Ҫ�r(sh��)��ע����ǣ�F(xi��n)PGA��(n��i)������(g��)����ģ�K���ǿ��Բ��в����ģ�����ó����˼·ȥ���������ϕ�(hu��)���������(du��)������������(d��ng)��DSP���ˡ�
3 ������ìF(xi��n)�е��YԴ��
�o�蠎(zh��ng)�h���������ѽ�(j��ng)������ͽ�ְ�һ��(g��)Spartan-3E��������С��ϵ�нo��M�ˣ�����һ��(g��)I2C�ӿڣ�������һ��(g��)��̫�W(w��ng)��MAC����呟�߀���ԣ��ڌ�(sh��)�H���(xi��ng)Ŀ��ÿ��(g��)���Լ�ȥ���Dz���ȡ�ģ�������ìF(xi��n)�е��YԴ�Ƿdz���Ҫ�ġ�������ÿ��(g��)�˵��O(sh��)Ӌ(j��)������Ҫע��e�ۣ�������(j��ng)�õò��e(cu��)�Ĺ���ģ�K�J(r��n)�����ƺ��ęn�Ա����Լ�������ʹ�ã��ٴ�FPGA�ďS�̶�������ܛ���Ѓ�(n��i)ǶһЩ���M(f��i)�Ĺ���ģ�K������(j��)�Լ�����������`����M(j��n)������ʹ�á���(d��ng)��(li��n)�W(w��ng)�r(sh��)������Ϣ�������������ɣ��������Է������һЩ�_Դ����^(q��)���ҵ��Լ���Ҫ�Ė|����������www.openhw.org��^(q��)����Ϳ����ҵ������d�ܶ�����FPGAͬ�ʂ��_�l(f��)���(y��n)�C�^�Ĺ���ģ�K������І��}߀��������^(q��)��(n��i)ͬ�����M(j��n)�л���(d��ng)��������ԃ�ȣ�Ҫ���@Щ���M(j��n)���ֶζ����ϡ���(d��ng)Ȼ�����˾��ؔ(c��i)��������Ҫ����̵ĕr(sh��)�g��(n��i)�Ƴ��a(ch��n)Ʒ�������Ե�FPGA�S�̵ľW(w��ng)վ�ϣ�����������լ��MĿ������IP, �@Щ����FPGA�S�̕�(hu��)ͬ�����J(r��n)�C�^��(li��n)�ˏS�̹�ͬ�Ƴ����ģ������Է��ĵ�ʹ�á��D3��Xilinx��˾�����M(f��i)����I(l��ng)��ġ���(sh��)���@ʾ�����ṩ��ϵ��IPʾ����
�D3 Xilinxͬ(li��n)�ˏS���ṩ�����ڡ���(sh��)���@ʾ������ϵ��IP
FPGA�ĸ��M(j��n)��
���g(sh��)���ڲ���l(f��)չ���������Ը���IJ�����FPGA�����������ܺ��ٶ��ϵ���ߎ��o�҂��������p�˵ĉ���Խ��Խ����ô��Č��I(y��)֪�R(sh��)��Ҫ�W(xu��)��(x��)����ô����O(sh��)Ӌ(j��)������Ҫ���գ���ô���ϵ�y(t��ng)������Ҫ��(sh��)�F(xi��n)����(du��)�Ñ�������(zh��n)ͬ��Ҳ�nj�(du��)FPGA�S�̵�����(zh��n)������܉��Ñ�����̵ĕr(sh��)�g��(n��i)�O(sh��)Ӌ(j��)���M����������Ҫ�Įa(ch��n)Ʒ��FPGA�S�����R������Ҫ�Ć��}��ͬ�r(sh��)ҲӰ�����������(w��)ģʽ�ĸ�׃���ڴ����e�����J(r��n)��ĿǰFPGA�S����Ҫע���һЩ���}��
Altera��˾�a(ch��n)Ʒ����I(y��)�Ј�(ch��ng)������Vince Hu�u(p��ng)Փ�f����FPGA�c̎�����ĽM�ϑ�(y��ng)��Ѹ�ٔU(ku��)չ����Ƕ��ʽϵ�y(t��ng)�O(sh��)Ӌ(j��)���_�l(f��)�µĶ��Ʈa(ch��n)Ʒ��ͨ�^Ƕ��ʽӋ(j��)����Alteraʹ��܇�����I(y��)��܊�º͟o�����Ј�(ch��ng)���O(sh��)Ӌ(j��)�ˆT�܉��چ�һ�O(sh��)Ӌ(j��)�����У����������̎����������ϵ�y(t��ng)�Լ�IP֧�ֵ��o��ϵ�y(t��ng)��������ϵ�y(t��ng)���ɱ�����Ѹ�ٵČ��a(ch��n)Ʒ�����Ј�(ch��ng)�������ϵ�y(t��ng)���`���ԡ���
����ԓӋ(j��)����һ���֣�Altera���^�m(x��)��չĿǰ��Ƕ��ʽ�������Ӌ(j��)����(li��n)��ARM��Intel��MIPS���g(sh��)��˾�Լ�FPGA�I(y��)��Ķ���(g��)������顣���⣬Altera���c�����f(xi��)��������(qi��ng)�O(sh��)Ӌ(j��)���̣�֧��Խ��Խ���FPGAǶ��ʽ̎���a(ch��n)Ʒ�����Ј�(ch��ng)��
Intel���ȫ��l(f��)���˼����Ƴ��Ļ���Atom�Ŀ�������̎�������@һ̎�����ڶ�оƬ���b�к���Intel Atom E600ϵ���Լ��䌦(du��)��Altera? FPGA����(du��)��ϣ�����Ì���I/O������Ӳ�����Ñ����ԣ��@�M(j��n)һ��������������`���ԣ�߀֧���_�l(f��)�ˆTѸ�ّ�(y��ng)��(du��)�����׃�����Ķ�ͻ�����O(sh��)Ӌ(j��)��(y��u)��(sh��)��
IntelǶ��ʽͨ�ŽM�����ü濂��(j��ng)��Doug Davis�f�����`������Ƕ��ʽ�O(sh��)Ӌ(j��)�ˆT���P(gu��n)�I����FPGA���g(sh��)�ṩ�˸�����x��Intel����l(f��)���˼���Altera FPGA�c����Intel Atom̎�����Ķ�оƬ���b�a(ch��n)Ʒ���^�m(x��)��Ƕ��ʽ�_�l(f��)�ˆT�ṩ�`������ܽ�Q��������
Altera߀¶�ϰ����cARM����˾�����˅f(xi��)�h���ڙ�(qu��n)����Cortex-A9̎�����ڃ�(n��i)�Ķ�N���g(sh��)��Altera����28nm FPGA���g(sh��)���ṩ����������(qi��ng)Cortex A9̎������ϵ�y(t��ng)�Įa(ch��n)Ʒ��Altera����2011��l(f��)���@Щ����ARM̎������������Ԕ��(x��)��Ϣ��
ARM̎�������T�Ј�(ch��ng)������Eric Schorn�f����ARM�J(r��n)�R(sh��)��FPGA�I(y��)�����Ҫ�ԣ��dz�ϣ���c�������һ���f(xi��)�����ԝM��Ƕ��ʽ�O(sh��)Ӌ(j��)�ˆT��(du��)�`���Ե�����ARM�ڵ��ġ�������̎����IP�ϵ��I(l��ng)�ȃ�(y��u)��(sh��)�cAltera�Č��I(y��)FPGA���g(sh��)��Y(ji��)�ϣ�ʹ�҂��܉���ù���ܛ�����́��M(j��n)һ������`���ԣ�����ܛ���_�l(f��)�ˆT��Ӳ���O(sh��)Ӌ(j��)�ˆT���ٸ��N��(y��ng)�õ��_�l(f��)����
Altera߀�M(j��n)һ���U(ku��)չ��ܛ��̎����ϵ�Юa(ch��n)Ʒ��������2011���ϰ����Ƴ�����MIPS���g(sh��)��˾MIPS32̎�����wϵ�Y(ji��)��(g��u)��MP32ܛ��̎������MP32��Altera��MIPS���g(sh��)��˾�Լ���Ҫ�Ñ��^ȥ�������Ѕf(xi��)���ĽY(ji��)������ᘌ�(du��)Altera����������Altera Nios IIǶ��ʽ̎�����Լ��������ܛ��CPUϵ�Юa(ch��n)Ʒ���O����S����FPGA����ʹ�õIJ���ϵ�y(t��ng)�͑�(y��ng)�ó���
MIPS���g(sh��)��˾�Ј�(ch��ng)������Art Swift�f�����҂��dz����d�Ŀ�����ͨ�^MIPS32�wϵ�Y(ji��)��(g��u)�S�ɣ�Altera�ṩMP32ܛ��CPU�����������(qi��ng)�ˮ�(d��ng)�����O(sh��)Ӌ(j��)�wϵ�Y(ji��)��(g��u)���`���ԡ��S��̎�����Ϳɾ���߉���ɵļ��٣���Alteraƽ�_(t��i)�ό�(sh��)�F(xi��n)MIPS32�wϵ�Y(ji��)��(g��u)��Ƕ��ʽ�O(sh��)Ӌ(j��)�ˆT�ܺõ��x��
������ĩ��Altera���ṩQsysϵ�y(t��ng)���ɹ��ߣ�����Quartus II�_�l(f��)ܛ����һ���֡����ØI(y��)���ׄ�(chu��ng)��FPGA��(y��u)��оƬ�W(w��ng)�j(lu��)���g(sh��)��Qsys�܉��ṩ�惦(ch��)��ӳ��͔�(sh��)��(j��)ͨ·��(li��n)��ʹAltera SOPC Builder���ߵ�����������ɱ���ͬ�r(sh��)֧�֘I(y��)���(bi��o)��(zh��n)IP�ӿڣ����磬AMBA��Qsys������ʹ�÷����SOPC Builder���棬֧���c�F(xi��n)��Ƕ��ʽϵ�y(t��ng)��ֲ�ĺ�����ݡ����ң��@һ��(j��)��(li��n)���g(sh��)��֧�ַ��O(sh��)Ӌ(j��)���u�M(j��n)ʽ���g�Լ������������÷�����
]]>��Table 3�����ژI(y��)��ȵ����J(r��n)������(gu��)��(j��)��Ř�(bi��o)��(zh��n)�f(xi��)�h(STSC)���x�ďV����ʽһ�[��������������������ǘӣ��O(sh��)�������̿��M(j��n)�б�����x��-�߷ֱ���(HD)߀�ǘ�(bi��o)��(zh��n)�ֱ���(SD)��16:9߀��4:3������߀�Ǹ��В���ȡ��mȻҲ��ASSP(�ض���(y��ng)�Ø�(bi��o)��(zh��n)�a(ch��n)Ʒ)������(j��ng)����ÿ�N��(bi��o)��(zh��n)��Ҫ��ͬ��оƬ��FPGA��Q����������֧�ֳ��^HDTVҪ��Ĕ�(sh��)��(j��)��ݔ���ʣ��@��ζ��һ��(g��)��������֧�������@Щ��ʽ��ֻ��Ҫ����(j��)�O(sh��)�����Ҫ�M(j��n)�����¾��̾Ϳ����ˡ��@�ɜp����I(y��)����������(xi��ng)Ŀ��ͬ�r(sh��)߀�ų���ASSP����(y��ng)�̿��ܴ��ڵĹ�؛�L(f��ng)�U(xi��n)��
��Ҫ�M(j��n)�И�(bi��o)��(zh��n)�x�����һ��(g��)������ɫ�ʿ��g׃�Q���D��������C(j��)�ɼ��M(j��n)���Ժ�����É��s�㷨��(du��)���M(j��n)��̎������ͨ�^��������ֱ�����ҕ�C(j��)�@ʾ�������^����Ҳ����ˡ����s�㷨�������@�ӵ���(sh��)��������ݔһ���D�������ɫ����Ϣ�Ϳɵõ��M���Ч������RGB���t���G���{(l��n)����ʽ�M(j��n)�ЈD��̎���ǿ��еġ���RGB��ʽ�У�ÿһ�����Ԍ�(du��)��(y��ng)ÿһԭɫ������(g��)8��10λ�ց����x�����������ی�(du��)�⾀�l�V��ijЩ���ֱ��������ַ���(y��ng)ҪС����˿����������Ȼ�(Y)�Լ�ɫ����̖(h��o)(��CrCb)����ʾ�D���@�����ĺ�̎����Ҫ�^С�Ĵ惦(ch��)�͔�(sh��)��(j��)�����������Ҫһ�N�C(j��)�Ɓ��M(j��n)�в�ͬɫ�ʸ�ʽ�g���D(zhu��n)�Q���@Ҳ�Q��ɫ�ʿ��g׃�Q��һ��֪����һ��(g��)ɫ�ʿ��g����һ��(g��)ɫ�ʿ��gӳ���ϵ��(sh��)����Ӳ����(sh��)�F(xi��n)�@Щ�·�ͷdz���(ji��n)�Ρ�
���磬�ڔ�(sh��)���ҕϵ�y(t��ng)�У�YerCbɫ�ʿ��g�ɰ���ʽ�D(zhu��n)�Q��RGBɫ�ʿ��g��
R\ = 1.164 (Y-16) + 1.596(Cr -128)
G\ = 1.164 (Y-16) - 0.813 (Cr -128) - 0.392(Cb-128)
B\ = 1.164 (Y-16) + 1.596 (Cr-128)
����R\G\B\��٤�R(Gamma)У��RGB��(sh��)ֵ������CRT�@ʾ���У����յ��Ŀ�����̖(h��o)���Ⱥ�ݔ����(qi��ng)���g�ǷǾ����P(gu��n)ϵ���@ʾ��ǰ��٤�RУ����̖(h��o)��ʹ������̖(h��o)���Ⱥ�ݔ����(qi��ng)�ȵ��P(gu��n)ϵ���Ի���ݔ������Ҳ������һ�����ֵ���Ķ����͈D�����ڂ�ݔ����������ж�N���ܵČ�(sh��)�F(xi��n)�����������ô惦(ch��)����߉��Ƕ��ʽ�˷�����FPGA�Ќ�(sh��)�F(xi��n)����ij˷����ܡ�
��(d��ng)��Ҫ�ڴ���ɫ�ʿ��g֮�g�M(j��n)���D(zhu��n)�Q�x��r(sh��)�����ÿɾ���ɫ�ʿ��g׃�Q���ă�(y��u)�c(di��n)�dz����@�������̎��ʾ��YCrCb �cRGB׃�Qһ�ӣ�YUV�Լ�YPrPb �����c����Ƶ��㷨��ֻ��ϵ��(sh��)������ͬ���mȻ�И�(bi��o)��(zh��n)��ɫ�ʿ��g������ͬ�O(sh��)���g��Ҫ�����S�ͬ�ĵط����߷ֱ��ʈDƬ���������c��(bi��o)��(zh��n)���x��ͬ��ɫ�ʿ��g�������пɾ��̵�׃�Qϵ��(sh��)���O(sh��)���������֧���κ�ݔ��ֱ��ʡ�ͬ�r(sh��)�����Ҫ��Ԓ����ͨ��ɫ�ʿ��g׃�Q֧��Ҳ��������������������ÿɾ���߉��Ԓ���@ͨ����Ҫ���KASSP����(d��ng)Ȼ������FPGA������ϵ�y(t��ng)�ܘ�(g��u)߀�ɸ���(j��)��(y��ng)���{(di��o)������(y��ng)���㷨���Ķ�ʹ���ܡ�Ч�ʻ����ͬ�r(sh��)��(sh��)�F(xi��n)���
FPGA��(j��ng)�������͔�(sh��)��(j��)�������I(y��)�V�������W(w��ng)�j(lu��)�ӿ��O(sh��)�䡣�ɾ��̼ܘ�(g��u)�dz��m�υf(xi��)�h�����͔�(sh��)��(j��)����ʽ̎������FPGA�ṩ�ĸ��ٲ��I/O��LVDS��ʹFPGA���Էdz�����ٶ���Ƭ���x�����Ƭ��ݔ����(sh��)��(j��)��FPGA߀�����ھ���h(hu��n)�������ͥ�W(w��ng)�j(lu��)���W��D(zhu��n)VB(��(sh��)���ҕ�V��)(li��n)���������IEEE1394���ٴ��п������锵(sh��)���ҕ�a(ch��n)Ʒ�Ę�(bi��o)��(zh��n)�B�ӷ�ʽ���o����(bi��o)��(zh��n)����IEEE802.11 �� HiperLAN2Ҳ�����h������ж��_(t��i)�ҕ�ļ�ͥ�W(w��ng)�j(lu��)���B�ӷ�����
�S�������S��^(q��)�߷ֱ��ʏV���ij��F(xi��n)��ҕ�l��̖(h��o)̎��Ҫ��O�������ˡ����磬����1920��1080�ֱ��ʡ�24λ���غ�ÿ��30�����В���ĸ߷ֱ����ҕ�C(j��)����Ҫ�s1.5Gbps�Ŀ���δ���s��������ʹ��߀�]�Ќ�(sh��)�H�M(j��n)�и߷ֱ��ʈD��V���ĵ^(q��)����ֱ�����������������A���У����õ�Ҳ�Ǹ߷ֱ��ʈD��
�F(xi��n)�����µĿɾ���߉�������ж���(g��)��֧�ִ��(sh��)��(j��)���ʵ�LVDS(�͉������̖(h��o))I/O����ʹ��ᘌ�(du��)���M(f��i)�Ј�(ch��ng)�ĵͳɱ�������Ҳ���@�ӵ�I/O֧�֡��@��ζ��δ���s��ҕ�l��(sh��)��(j��)��ݔ���ݔ���������M(j��n)�Ќ�(sh��)�r(sh��)̎����HDTV����һ��(j��)�Č�(sh��)�r(sh��)ҕ�l̎�����S�O(sh��)Ӌ(j��)�ˆT�p����Ҫ���ⲿ�惦(ch��)����(sh��)����Ŀǰ���������O(sh��)Ӌ(j��)��ҕ�l��̖(h��o)̎�������ֳɞ�ƿ�i����ˬF(xi��n)�еĔ�(sh��)���ҕϵ�y(t��ng)�н�(j��ng)�����ö���(g��)���惦(ch��)�͔�(sh��)��(j��)���_��������FGPA�IJ�����̖(h��o)̎��������ζ����С�ģ������Ύ��惦(ch��)���ɣ�����(sh��)��(j��)���_���t����ȫʡ������(bi��o)��(zh��n)DSP�����ܷ���ľ��ތ�(d��o)�²��ò��_�l(f��)���錣�õ�оƬ����ý�w̎���������˷��@Щ���}��Ȼ������(sh��)�C���@Щ���������ڷ����Oխ��һЩ��(y��ng)���У�����̫���`���ȱ�c(di��n)��ͬ�r(sh��)߀������ƿ�i���ڡ���FPGA�����t����ͨ�^���ƣ��������ʺ����ܷ����ṩ����Ч�ʡ��O(sh��)Ӌ(j��)�ˆT߀�������O(sh��)Ӌ(j��)��e���ٶ�֮�g�M(j��n)�����ԣ����ҿ��Ա�DSP�͵ö�ĕr(sh��)�������ɽo���Ĺ��ܡ�
��ǰ������F(xi��n)PGA�^ȥ�H���ڌ��I(y��)�ďV��ϵ�y(t��ng)�У���Ħ��������ζ����������u��(y��ng)���ڴ��������M(f��i)�a(ch��n)Ʒ�С��Ԕ�(sh��)���ҕ���������ЙC(j��)픺й�����ȫ���ɵ��ҕ�У���˔�(sh��)���ҕ�ɽ��Ք�(sh��)�֏V����ͨ���@����ͨ�^��(bi��o)��(zh��n)�쾀�������M(f��i)�ğo����̖(h��o)����δ���Įa(ch��n)Ʒ�����S���Ձ�����|���l(w��i)�ǻ�DSL��·��ݔ?sh��)����?h��o)��FPGA�ɑ�(y��ng)���ڔ�(sh��)���ҕ�C(j��)��(n��i)���S�ಿ�֣�1��ʾ�������(bi��o)��(zh��n)оƬ�M�g�ġ�(li��n)�Y(ji��)߉(glue logic)��һ����FPGA�ď�(qi��ng)�(xi��ng)�����S���D��̎���΄�(w��)(��ɫ�ʿ��g׃�Q)�Լ��W(w��ng)�j(lu��)�ӿ�(��IEEE 1394���F(xi��n)��Ҳ���ڵͳɱ��ɾ���߉������(n��i)��(sh��)�F(xi��n)��
�@һ���D��̎���΄�(w��)��FPGA��ɵ�څ��(sh��)��һ��(g��)��Ҫ�(q��)��(d��ng)�������ԘI(y��)�����Q�ġ���(sh��)���ںϡ���Ŀǰ�a(ch��n)�����@��һЩ����ͨ�^�O�����Ă�ݔ�ŵ�(��o��)�l(f��)�ʹ���ҕ�l��(sh��)��(j��)��ͬ�r(sh��)߀Ҫ���ֿɽ��ܵķ���(w��)�|(zh��)��(QoS)���@��(d��o)��(du��)��θ����e(cu��)�`У���㷨�����s�͈D��̎�����g(sh��)�M(j��n)�з�������V�����о����������ஔ(d��ng)һ���ֹ����LJ��@����FPGA�����M(j��n)�еġ�
����FPGA���O(sh��)Ӌ(j��)�ˆT����ʹ�Լ��Ę�(bi��o)��(zh��n)���ݵ�ϵ�y(t��ng)�c��(j��ng)��(zh��ng)��(du��)�ֵĮa(ch��n)Ʒ���ֲ������MPEG-2���s�������������Ԍ�MPEG̎����ؓ(f��)؟(z��)��MPEG��(bi��o)��(zh��n)�㷨�е�DCT(�xɢ����׃�Q)����ж�d��FPGA�������M(j��n)��̎�����Ķ����ӎ�����DCT���䷴׃�Q������FPGA��Ч�،�(sh��)�F(xi��n)�������ѽ�(j��ng)�н�(j��ng)�^��(y��u)����IP�˿�ֱ�ӑ�(y��ng)�õ�����MPEG���O(sh��)Ӌ(j��)֮�С���MPEG���a������߀���S��δ���x��ģ�K(���\(y��n)��(d��ng)�A(y��)�y(c��))��ͨ�^��FPGA�Y(ji��)��(g��u)�м��������@Щģ�K�Č��м��g(sh��)�͘�(bi��o)��(zh��n)����DCT�@�ӵĹ��ܣ��Ϳ��Ԅ�(chu��ng)��������̎�펧�����_(d��)�����߈D���|(zh��)���ĵͳɱ��Ć�Ƭ��Q������ͨ�^����ϵ�y(t��ng)�H��ه�ژ�(bi��o)��(zh��n)ASSP��Q��������I(y��)�Ͳ��ٕ�(hu��)�б��Ј�(ch��ng)�J(r��n)��H���ṩ���ĎN��ƽ�Q������Σ�U(xi��n)��
FPGA߀��ʹ���Įa(ch��n)Ʒ����������Ј�(ch��ng)�������ڬF(xi��n)��(ch��ng)���b�֞����a(ch��n)������I(y��ng)�յ�����������(sh��)FPGA������SRAM���g(sh��)���Ķ����_�l(f��)�ĸ���(g��)�A�ζ��������،�(du��)�����M(j��n)�����¾��̡��@ʹϵ�y(t��ng)���{(di��o)ԇ���麆(ji��n)�Σ�����߀��ζ�������Ҫ��Ԓ��С�ĸ�׃Ҳ���������ϵ��a(ch��n)Ʒ��ȥ���@�п��ܕ�(hu��)���ڿ͑�Ҫ��ĸ�׃��Ҳ�ɿ��������ژ�(bi��o)��(zh��n)���°汾��������
]]>
���磬�ڞ�a(ch��n)Ʒ�x�� FPGA �r(sh��)�����ĵĿ��]׃��Խ��Խ��Ҫ���ܿ�����һ���O(sh��)Ӌ(j��)��(hu��)��Ҫ�ڹ����A(y��)�㲻׃�����С������r�£����ɸ�������Ժ͌�(sh��)�F(xi��n)���ߵ����ܡ�
�ڱ����У��Ҍ��������Ľ����������ĺ�̎��߀����B Virtex-5 ��������ʹ�õĶ�N���g(sh��)�ͽY(ji��)��(g��u)�ϵĸ��£��������ṩ������͵Ľ�Q���������Ҳ���(hu��)�����������κ��ۿۡ�
�������ĺ�̎
������ FPGA �O(sh��)Ӌ(j��)�������ă�(y��u)��(sh��)���H���ܝM������������ɢ��Ҫ���mȻ�M��Ԫ��ָ��(bi��o)��(du��)�����ܺͿɿ���ʮ����Ҫ������Ό�(sh��)�F(xi��n)�@һ�c(di��n)��(du��)��ϵ�y(t��ng)�ɱ��͏�(f��)�s�Զ��������Ӱ푡�
���ȣ����� FPGA �Ĺ���ʹ���܉�ʹ�ø����˵��Դ���@�ӵ��Դʹ�õ�Ԫ����(sh��)���^�٣�����ռ�õ� PCB ��eҲ�^С�������ܵ��Դϵ�y(t��ng)�ijɱ�ͨ����ÿ��0.5��1��Ԫ�������� FPGA ֱ�ӽ�����ϵ�y(t��ng)�����w�ɱ���
��Σ����ڹ���ֱ���cɢ�����P(gu��n)������ʹ���܉�ʹ�ø���(ji��n)�Ρ������˵ğ���������Q�������ںܶ���r�£��O(sh��)Ӌ(j��)�ߌ�������Ҫɢ����������ֻ��Ҫ��С�������˵�ɢ������
�����������������ζ�����ٵ�Ԫ�����͵������ضȣ���ˌ��������(g��)ϵ�y(t��ng)�Ŀɿ��ԡ����������ض�ÿ����10�棬���ஔ(d��ng)��Ԫ����������˃ɱ�����ˌ�(du��)����Ҫ�߿ɿ��Ե�ϵ�y(t��ng)���ԣ����ƹ��ĺ͜ض�ʮ����Ҫ��
���ģ�����(zh��n)�ͽ�Q����
FPGA �����κΰ댧(d��o)�w�������еĿ����ĵ����o�B(t��i)���ĺ̈́�(d��ng)�B(t��i)����֮�͡��o�B(t��i)������Ҫ�ɾ��w�ܵ�й©������𣬼����w�ܼ�ʹ��߉�ϱ��P(gu��n)���r(sh��)����Դ�O��й©����©�O��ͨ�^������й©����С�������(d��ng)�B(t��i)�������������Ļ� I/O ���_�P(gu��n)�^�������ĵ��������c�l�����P(gu��n)��

�D1��85��r(sh��)���o�B(t��i)���ı��^
�o�B(t��i)����
�ڿsС���w�ܳߴ�r(sh��)�����磬��90�{��65�{�ף���й©�������(hu��)�����¹�ˇ�Y(ji��)�c(di��n)��ʹ�õĶ̜��L(zh��ng)�ͱ�����ʹ��������ľ��w�ܵĜϵ��^(q��)��ͨ�^����й©��
��90�{�� Virtex-4 ϵ�Юa(ch��n)Ʒ�У�Xilinx ��˾ʹ���ˡ����ŘO�����ӡ��Ĺ�ˇ���g(sh��)���� Xilinx �·�O(sh��)Ӌ(j��)���ṩ��һ�N��(qi��ng)��������ֹ©늹��ߡ���ǰ�״� FPGA �У�ʹ�ÃɷN������ȣ����������� FPGA �����и����ܡ�����늉��ľ��w�ܣ������������ I/O ģ�K�гߴ��^����Ҫ���ܴ�늉��ľ��w�ܡ���(ji��n)�ε��f�������ŘO�����ӡ�ָ����һ�N���g��Ȗ����ľ��w�ܣ�����©늱ȱ������ĺ��ľ��w��ҪС�öࡣ
�����g�������ľ��w��������������������P(gu��n)�I���ܵ��·�����O(sh��)�ô惦(ch��)��������Ҫ��(du��)׃���Ėʼn��M(j��n)�п����_�P(gu��n)푑�(y��ng)���·�����ݔ�T���С���������©����ľ��w��ֻ��������Ҫ�����_�P(gu��n)�ٶȵ�·�����֡��Y(ji��)������������©늱����pС��ͬ�r(sh��)�������ܱ���һ�� FPGA �кܴ���ߡ�
���ŘO�����ӹ�ˇʹ Virtex-4 �����ȸ�(j��ng)��(zh��ng)��90�{�� FPGA ���o�B(t��i)������ƽ���p���˳��^70%���@һ�Y(ji��)���dz��ɹ������ Virtex-5 ϵ�Юa(ch��n)Ʒ�д���ʹ�����@һ���g(sh��)����65�{��ˇ�Y(ji��)�c(di��n)�Ͻ���©늡�
�mȻ�I(y��)���A(y��)�y(c��)65�{���������o�B(t��i)���Č���(hu��)�д������ߣ����LjD1�@ʾ�����ŘO�����ӹ�ˇʹ65�{�� Virtex��������ģ��ض���ߣ������l�����_(d��)�����c�ߴ��ஔ(d��ng)?sh��)?0�{�� Virtex-4������ͬˮƽ���o�B(t��i)���ġ���ˣ�Virtex-5 ϵ�Юa(ch��n)Ʒ��(j��ng)��(zh��ng)�Ը����� FPGA �a(ch��n)Ʒ��ȣ����o�B(t��i)���ķ�����������ă�(y��u)��(sh��)��
��(d��ng)�B(t��i)����
��(d��ng)�B(t��i)���Ğ�65�{�� FPGA����һЩ�������������(zh��n)����(d��ng)�B(t��i)���ĵĹ�ʽ�飺
��(d��ng)�B(t��i)���� = CV2f
����C�ǽY(ji��)�c(di��n)�_�P(gu��n)�r(sh��)����ݣ�V���Դ늉���f���_�P(gu��n)�l�ʡ�65�{��ˇ��(ji��)�c(di��n)ʹ FPGA ��߉���������ܱȂ��y(t��ng)���������@����ߣ�Ҳ�����f����ĽY(ji��)�c(di��n)�����ڸ��ߵ��l���ϡ������������ėl����׃����(d��ng)�B(t��i)���Č���(hu��)����
���ǣ���(du��)��65�{��ˇ��(ji��)�c(di��n)�Ą�(d��ng)�B(t��i)���Ķ��ԣ�Ҳ��һ��(g��)����Ϣ��FPGA ���ĵ��Դ늉���V���ͽY(ji��)�c(di��n)��ݣ�C��ͨ����ÿһ���¹�ˇ�ж���(hu��)�½����Ķ�ʹ�Ä�(d��ng)�B(t��i)���ı���һ�� FPGA �����½���
Virtex-5 �����У������Դ늉���VCCINT����Virtex-4 ����ʹ�õ�1.2V�½���1.0V�����ڼ������׃С���c��С�ľ��w�����P(gu��n)�����Լ�߉�K�g�Ļ�(li��n)���L(zh��ng)��׃�̡����׃С��ʹ�Y(ji��)�c(di��n)��ݜpС�����⣬Virtex-5 �����ڽ��ٻ�(li��n)��֮�gʹ����һ�N��늳���(sh��)�^�͵IJ��ϡ�
Virtex-5 ������ƽ���Y(ji��)�c(di��n)��ݱ�Virtex-4 ������s�pС��15%������늉����͎����ĺ�̎�������ஔ(d��ng)�ڌ� Virtex-5 �����ĺ��Ą�(d��ng)�B(t��i)���Ľ�����35-40%��
������ˇ�ߴ�sС����65�{���������Ĺ��е�35-40%�Ą�(d��ng)�B(t��i)���Ľ����⣬Virtex-5 �����ļܘ�(g��u)��(chu��ng)�£�߀���M(j��n)һ������ÿ��(g��)�O(sh��)Ӌ(j��)�Ĺ��ġ������(sh��)�����ӄ�(d��ng)�B(t��i)�����еĽY(ji��)�c(di��n)��ݣ�����߉�����g�Ļ��B������ġ����� Virtex-5 �ܘ�(g��u)�ڃɂ�(g��)����ĸ����ϜpС���B����ݣ�
��Virtex-5�Ŀ�����߉ģ�K��CLB�� �ǻ���6ݔ����ұ���6-LUT�� ߉�Y(ji��)��(g��u)�ģ�����ǰ����������ʹ��4ݔ����ұ����@��ζ����ÿ��(g��) LUT ���܉�?q��)��F(xi��n)�����߉���ஔ(d��ng)���^�ٵ�߉��(j��)���Ķ������ˌ�(du��)߉����֮�g������B��������
��
��Virtex-5 �Ļ�(li��n)�Y(ji��)��(g��u)Ŀǰ�����ˌ�(du��)�Ǿ���(du��)�Q���B������ζ��ÿ��(g��) CLB �c����������ģ�K������̎�ڌ�(du��)�Ǿ�λ�õ�ģ�K��֮�g����ֱ�ӵġ���һ���B�ӡ���(d��ng)߉����֮�g��Ҫ�B�ӕr(sh��)���@һ�B�Ӹ��п��ܳɞ鿂�����С�ġ���һ���B�ӣ��������Ļ�(li��n)�Y(ji��)��(g��u)��(du��)����ͬ���B�ӆ��}���ܕ�(hu��)��Ҫ�ɂ�(g��)�����Y(ji��)�c(di��n)��

�D2�� Ӌ(j��)��(sh��)����(bi��o)��(zh��n)�O(sh��)Ӌ(j��)�Ą�(d��ng)�B(t��i)���ı��^
6-LUT �Y(ji��)��(g��u)���M(j��n)�Ļ�(li��n)ģʽ��ͨ�^����ƽ���Y(ji��)�c(di��n)��݁����ͺ��ĵĄ�(d��ng)�B(t��i)���ģ�Ч���h(yu��n)�h(yu��n)���^�Hʹ��65�{��ˇ�������ĸ��M(j��n)���D2�@ʾ�ˁ��Ԙ�(bi��o)��(zh��n)�O(sh��)Ӌ(j��)�ĺ��Ą�(d��ng)�B(t��i)���ĵĜy(c��)���Y(ji��)��������ÿ��(g��) Virtex-5 ������ Virtex-4 �����ж���1024��(g��)8λӋ(j��)��(sh��)�����@Щ��(sh��)�H�Ĝy(c��)���Y(ji��)���@ʾ����ˇ�ͽY(ji��)��(g��u)�ϵĹ�ͬ��(y��u)���������Ą�(d��ng)�B(t��i)���ĵĽ��ͳ��^��50%��
ӲIPģ�K
Virtex-5�����а�����ӲIPģ�K�����T�Á팍(sh��)�F(xi��n)һЩ���ù��ܵ��·���Ĕ�(sh��)�������^�I(y��)�������κ�һ�� FPGA�����ʹ��ͨ�� FPGA ߉���ԣ�ʹ�ô��d�@Щģ�K�� FPGA �O(sh��)Ӌ(j��)�팍(sh��)�F(xi��n)�@Щ���ܣ����M(j��n)һ����������
�c FPGA �Y(ji��)��(g��u)��ͬ���@Щ���õ�ģ�K��ֻ�Ќ�(sh��)�F(xi��n)��Ҫ��Ĺ��ܱ���ľ��w�ܡ����қ]�пɾ��̵Ļ�(li��n)����˻�(li��n)�����С���^�ٵľ��w�ܺ��^С�ĽY(ji��)�c(di��n)����ܽ����o�B(t��i)�̈́�(d��ng)�B(t��i)���ġ��Ķ�ʹ�@Щ����ģ�K�ڌ�(sh��)�F(xi��n)��ͬ���ܵ�ͬ�r(sh��)������ֻ��ʹ��ͨ�� FPGA �Y(ji��)��(g��u)��ʮ��֮һ��
���������͵Č���ģ�K�⣬Virtex-4 �������ںϵĺܶ�ģ�K���� Virtex-5 �����ж��������O(sh��)Ӌ(j��)���������µ����ԣ�������ܣ������������磬Virtex-4 ϵ����18-Kb �� block RAM �惦(ch��)���� Virtex-5 �����б����ӵ���36-Kb��ÿ��(g��) block RAM �ܱ��ֳɃɂ�(g��)��(d��)���� 18-Kb �Ĵ惦(ch��)�����Ա����¼��� Virtex-4 ���O(sh��)Ӌ(j��)��
��Ȥ���ǣ��Ĺ��ĵĽǶȁ�����ÿ��(g��) 18-Kb ����ģ�K�Ƀɂ�(g��) 9-Kb �������惦(ch��)��И�(g��u)�ɡ���(du��)�ڴ����(sh��)�� block RAM ���ã��κΌ�(du��)�� block RAM���x��Ո(q��ng)��һ��ֻ��Ҫ�L�� 9-Kb �����惦(ch��)���е�һ��(g��)���������� 9-Kb �惦(ch��)�����ڲ����L���r(sh��)����Ч�ء��P(gu��n)�ࡱ�����^����65�{��ˇ�������Ĺ��Ľ��͵Ļ��A(ch��)�ϣ��@�N�Y(ji��)��(g��u)��ʹ�����M(j��n)һ��������50%���@һ��(du��)��9-kB ģ�K�ġ�ƹ�ҡ��L�����µ� block RAM�Y(ji��)��(g��u)�����еģ��@����ζ��ʹ���@�(xi��ng)���ܲ���Ҫ�Ñ���ܛ�����M(j��n)�п��ơ����܄�(d��ng)�B(t��i)���Ԅ�(d��ng)���M(j��n)�У�ʹ����ʹ�� block RAM���O(sh��)Ӌ(j��)�����˴����Ĺ��ģ����Ҳ���(hu��)Ӱ�ģ�K�����ܡ�
Virtex-5 �����Ќ��õ� DSP Ԫ��Ҳ�M(j��n)���˴����ĸ��M(j��n)���Ԍ�(sh��)�F(xi��n)����Ĺ��ܣ�������ܣ�������������Ƭ�cƬ�ı��^�У����͵� Virtex-5 DSP Ƭ�Ĺ��ı� Virtex-4 DSP Ƭ�Ĺ��Ľ����˴�s40%���@��Ҫ?d��)w����ǰ����ӑՓ��65�{��ˇ��늉�����ݵĜpС��
Ȼ�������� Virtex-5 DSP Ƭ���и���(qi��ng)�Ĺ��ܺ��V���Ľӿڣ��S�� DSP �\(y��n)��ͨ�^�����@Щ���ӵĹ����M(j��n)һ�������˹��ġ����S����r�£���(d��ng)ʹ������ DSP Ƭ��ȫ�����ܕr(sh��)����������߿ɽ���75%��Ո(q��ng)ӛס��ʹ�㲻�����O(sh��)Ӌ(j��)һ��(g��) DSP �a(ch��n)Ʒ��Ҳ��ʹ�� DSP Ƭ�팍(sh��)�F(xi��n)��(bi��o)��(zh��n)��߉���ܣ�Ӌ(j��)��(sh��)�����ӷ�����Ͱʽ��λ�������@�ӕ�(hu��)���ژ�(bi��o)��(zh��n) FPGA ߉�Ќ�(sh��)�F(xi��n)ͬ�ӵĹ��ܹ�(ji��)ʡ���ġ�
����B�Ľ�(j��ng)�^���M(j��n)�Č���ģ�K�� Virtex-5 ϵ�е� LXT ƽ�_(t��i)�����а����ˎ�λ�Ĵ����հl(f��)�C(j��)�����Ը��_(d��) 3.125Gbps �����ʹ������@Щ ��SERDES�� ģ�K�ڌ�(sh��)�F(xi��n)�r(sh��)���ؿ��]����������ÿ��(g��) Virtex-5 LXT �����е�ȫ�p���հl(f��)�C(j��)�� 3.125Gbps ���ٶ��µĿ�����С��100���ߣ��cVirtex-4�����հl(f��)�C(j��)��Ƚ����˴�s75%��

�D3�������O(sh��)Ӌ(j��)�ЬF(xi��n)�� FPGA �Ĺ��ı��^
�Y(ji��)Փ
Xilinx ��˾�ƾõĄ�(chu��ng)�vʷ�܉��ݵ�20����ǰ��һ�K FPGA �İl(f��)������� Xilinx ��˾������(d��ng)Ȼ�سɞ��һ��������g(sh��)�Ќ�������������Ҫ�΄�(w��)�Ĺ�˾���c Virtex-4 ϵ�Юa(ch��n)Ʒһ�ӣ�Virtex-5 ����Ҳ������һϵ�й�ˇ�ͼܘ�(g��u)�ϵĸ��£��������ṩ�M���ܵ͵Ĺ��ĵ�ͬ�r(sh��)����Ȼʹ�������30%����ࡣ
��D3��ʾ��Virtex-5ϵ�Юa(ch��n)Ʒ���o�B(t��i)�����c Virtex-4 �����ஔ(d��ng)�����ȸ�(j��ng)��(zh��ng)�� FPGA �������@�ă�(y��u)��(sh��)������Ψһ��65�{�� FPGA��Virtex-5 �������ĵĄ�(d��ng)�B(t��i)���ı��Ј�(ch��ng)������������ FPGA ������35-40%�������� 6-LUT �͌�(du��)�Ǿ���(du��)�Q�Ļ�(li��n)�ȼܘ�(g��u)�ϵĸ��£�ʹ��(sh��)�H���Ą�(d��ng)�B(t��i)�����M(j��n)һ��������50%�����ϡ����⣬���Ô�(sh��)����ǰ�Č���ģ�K�M(j��n)һ�������˹��ġ�
���@ȡ�����P(gu��n)��������� Virtex-5 �����������ܵ��Y�ϣ�Ո(q��ng)?ji��n)L��www.xilinx.com/cn//power��
Xilinx ����������XPE��
2006��1��������Xilinx ���Ĺ�������XPE������һ�N������Ӕ�(sh��)��(j��)���Ĺ��Ĺ��ߣ�֧��VirtexTM-4 �������Ƴ��� Virtex-5 �� SpartanTM-3 FPGA ϵ�Юa(ch��n)Ʒ��XPE ���O(sh��)Ӌ(j��)�Á�����W(w��ng)�j(lu��)���Ĺ��ߣ����������� XilinxFPGA ϵ�Юa(ch��n)Ʒ�ڳ����O(sh��)Ӌ(j��)�r(sh��)ʹ�õ���Ҫ���Ĺ�Ӌ(j��)���ߡ��c�����Ĺ��Ĺ�Ӌ(j��)������ȣ�XPE ����Ҫ��(y��u)��(sh��)���ڸ��M(j��n)���Ñ����桢���ߵľ��Ⱥ͌�(du��)��Ҫ��(sh��)��(j��)���õ��@ʾ������
XPE �ĸ�Ҫ��@ʾ������ʹ�õ������������������YԴ��ͣ��������Դ늉������܉�ʹ�ø�Ҫ��ϵČ�(d��o)�����o����ԃ��Ԕ��(x��)����Ϣ��XPE ��(hu��)�Ԅ�(d��ng)�@ʾһЩ�D���������Ñ�(chu��ng)������ʹ�ÈD��
�^�l(f��)����ʼ�汾֮��Xilinx ����m(x��)�l(f��)����һЩ���°汾��XPE���������S������Ժ;��ȵ���ߡ�www.xilinx.com/cn/power���ṩ���@Щ�汾��������֧�ֵ� Virtex-5 ��Spartan-3E �������б���
Kevin Bixler
Xilinx��˾���Ĺ��߮a(ch��n)Ʒ�Ј�(ch��ng)���̎�
�������T
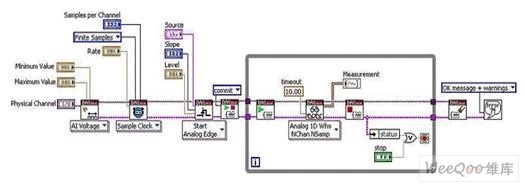
����NI LabVIEW FPGAģ�K����DAQϵ�y(t��ng)���_�l(f��)���`��������M(j��n)�Б�(y��ng)�ó����Ԍ�(sh��)�F(xi��n)���ݔ��/ݔ�������� �Ñ��o���A(y��)���˽�VHDL��Ӳ���O(sh��)Ӌ(j��)���ߣ���Ɍ�LabVIEW���aǶ��FPGAоƬ���@��Ӳ�����r(sh��)���ٶȺͿɿ��ԡ�
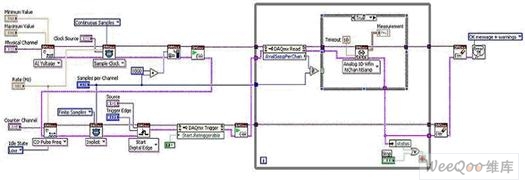
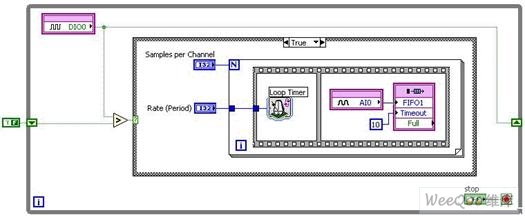
�����҂��ȏĔ�(sh��)��(j��)�ɼ�Ӳ���ij��ýM������Փ�}�� ���O(sh��)��������ģ��(sh��)�D(zhu��n)�Q��(ADC)����(sh��)ģ�D(zhu��n)�Q��(DAC)�͔�(sh��)��ݔ��/ݔ�������t����I/O��Ҫ����(j��)��(sh��)�H��������ij�N��ʽ�Ķ��r(sh��)�Ϳ��ơ� ���͵Ķ�ܔ�(sh��)��(j��)�ɼ��O(sh��)����ù����Rȫ��ASIC���M���˴����(sh��)�Ĺ���������
�������磺Mϵ��DAQ�O(sh��)��ͨ�^DAQ-STC2�����������Ӳ���M���Ķ��r(sh��)���|�l(f��)�� ����DAQӲ�����磺Rϵ��DAQ�O(sh��)�䣩�^(q��)�e�������ϵ������κΔ�(sh��)��(j��)�ɼ��O(sh��)�䣬��?y��n)��ڿ����O(sh��)�书�ܷ�������DAQ�û���FPGA��ϵ�y(t��ng)���r(sh��)������ȡ���˂��y(t��ng)ASIC���Ķ�ʹ������ģ�M�͔�(sh��)��I/O���ܸ���(j��)�ض���(y��ng)�ò�����������(y��ng)�����á� ��������FPGAоƬͨ�^NI LabVIEW FPGAģ�K�M(j��n)�о��̣��˕r(sh��)NI LabVIEW�Ĕ�(sh��)��(j��)��ģʽ���f�m�ã����^������һ�M�º���(sh��)������ӵ��O(sh��)��I/O��
����LabVIEW FPGA I/O��(ji��)�c(di��n)����ͨ�^NI-DAQmx����(sh��)ؓ(f��)؟(z��)��(sh��)�F(xi��n)��Ҋ���΄�(w��)���ܣ������`��������ڸ���(g��)ͨ��������\(y��n)�С� ͨ�^���¸����ֵă�(n��i)�ݣ��҂����˽�NI-DAQmx���ض���(sh��)�������W(xu��)��(x��)���ͨ�^����DAQ���Ƹ��(sh��)��(j��)�ɼ��΄�(w��)��
�������r(sh��)���|�l(f��)
������(sh��)�F(xi��n)��(j��)��(sh��)��(j��)�ɼ�������DAQ��Ҫ���ڶ��ƶ��r(sh��)���|�l(f��)�� �·��ķ��������Dչ�F(xi��n)�ˣ�NI-DAQmx������(sh��)�F(xi��n)���|�l(f��)ʽģ�Mݔ���΄�(w��)��
�����D1. ͨ�^NI-DAQmx��(sh��)�F(xi��n)���|�l(f��)ʽģ�Mݔ��
������D1��ʾ������DAQ��δʹ�ò�ͬ����(sh��)����ͨ��������ͨ�^����I/O��(ji��)�c(di��n)�ĺ���(sh��)�x����·ģ�M�͔�(sh��)��ͨ���� �҂�����ʹ��NI LabVIEW FPGA��I/O��(ji��)�c(di��n)���@�õ���ͬ���ܡ�
�����D2. ͨ�^����DAQ��NI LabVIEW FPGA��(sh��)�F(xi��n)���|�l(f��)ʽģ�Mݔ��
�����ψD�ț]��ᘌ�(du��)ȫ��ͨ�����ɘӕr(sh��)犡��|�l(f��)�����ú���(sh��)��Ҳ�]���_ʼ��ֹͣ��������΄�(w��)�� ���Ѓ�(n��i)�ݶ���1��(g��)��(ji��n)�ε�ģ�MI/O�xȡ��ȡ����ȫ�����r(sh��)���鱾��LabVIEW�Y(ji��)��(g��u)���磺Whileѭ�h(hu��n)�͗l���Y(ji��)��(g��u)�������ơ���������(g��)�����D����FPGAӲ����(n��i)��(zh��)�У�LabVIEW���a���\(y��n)�б��w�F(xi��n)��Ӳ�����r(sh��)���ٶȺͿɿ��ԡ�
�����҂���������˽�һ��ԓ�����D���\(y��n)�з�ʽ�� ģ�MI/O��(ji��)�c(di��n)����ָ��ij��(g��)�ɘ����ʣ���ʹ��Forѭ�h(hu��n)�ɼ�����(g��)�ӱ��� �c֮��(du��)��(y��ng)��ADC��I/O��(ji��)�c(di��n)���{(di��o)�Õr(sh��)��ؓ(f��)؟(z��)��(du��)ݔ����̖(h��o)�M(j��n)�Ќ�(sh��)�H��(sh��)�ֻ������ͨ�^Forѭ�h(hu��n)���ܶ��r(sh��)�� ������100 kHz���l�����M(j��n)����̖(h��o)�ɘӣ�ᘌ�(du��)ѭ�h(hu��n)�����t�ͱ���O(sh��)����10 ?s�� ѭ�h(hu��n)�Ķ��r(sh��)������(sh��)�ĵ�2݆ѭ�h(hu��n)�����_ʼ��_�����ض��ĕr(sh��)�g���t���Ñ�����܉�ͨ�^���Y(ji��)��(g��u)���C�ӱ�֮�g������ָ���ĕr(sh��)�g�g���� NI LabVIEW FPGA*��(qi��ng)��ėl���Y(ji��)��(g��u)����(sh��)�H���������ڷ��b����a��Ӳ���|�l(f��)�� �������еĺ���(sh��)�ͽY(ji��)��(g��u)��ͨ�^߉��Ԫ��Ӳ����(n��i)�\(y��n)�У����ԗl���Y(ji��)��(g��u)�_���_ʼ���Ќ�(sh��)�r(sh��)10 ?s�r(sh��)�g���ȵIJɘӡ� �����ָ�����ǣ����ڲ���λ��Ӳ���ӣ�ֻ�漰�ׂ�(g��)�Ӵεij���̎��������Ñ��o������΄�(w��)ID��ጷ���(n��i)����
�����ͻ���FPGA������DAQӲ�����ԣ��������ă�(y��u)��(sh��)���܉��Ƹ���r(sh��)���|�l(f��)������Ӳ�����M(j��n)����̖(h��o)̎���͛Q�ߡ� �F(xi��n)���҂��˽�һ�£�ᘌ�(du��)ij��Զ��x��(y��ng)�ã��茦(du��)ģ�Mݔ���|�l(f��)������Щ�ġ� ���҂�ϣ����2·ģ�Mݔ��ͨ����ij·늉����^ָ�������r(sh��)���|�l(f��)�ɼ�����ԓ������أ� ����NI LabVIEW FPGA������΄�(w��)�Ĉ�(zh��)�����練�ơ�
�����D 3. ͨ�^����DAQ��NI LabVIEW FPGA��(sh��)�F(xi��n)���Զ��x�|�l(f��)ʽģ�Mݔ��
�����@��҂��ѽ�(j��ng)������D�����˵�2��(g��)I/O��(ji��)�c(di��n)�͵�2��(g��)���^����(sh��)���Լ�1��(g��)����������(sh��)�� ����DAQӲ�������е�ģ�Mݔ��ͨ���ṩ����ADC�����2·ͨ���܉����ͬ���ɘӣ�ͬ�r(sh��)��ֻҪ�κ�1·ͨ����늉����^��ָ���������l���Y(ji��)��(g��u)���(hu��)��(zh��)�С��桱�l�������_ʼ��10 ?s�r(sh��)�g�����M(j��n)�вɘӡ� Ո(q��ng)ӛס��ȱ������DAQ�㲻����������Ƶ��|�l(f��)��������DAQӲ���ϑ�(y��ng)�Õr(sh��)���|�l(f��)��Ҫ���и������t��ܛ�����r(sh��)�팍(sh��)�F(xi��n)�� ����˺��҂�ϣ��ͨ�^�U(ku��)չ���O(ji��n)�ط�����2·ͨ��������ȫ��8·ͨ��������ϣ�����Ӕ�(sh��)���|�l(f��)������Ҫ��(ji��n)���Զ��x���a�� �����A(y��)�|�l(f��)������Ñ���Ɍ�(du��)ݔ��ͨ�������M(j��n)�вɘӲ�����(sh��)��(j��)������FIFO���_���� �|�l(f��)��һ�������xȡ��F(xi��n)IFO���_���ʹ˺�IJɘӱ�ɽ�(j��ng)��DMAͨ���������������C(j��)��
��������҂�ϣ������NI-DAQmx�(q��)��(d��ng)����(du��)��2ģ�Mݔ��ͨ���M(j��n)�вɘӣ��tԓ�����D�c�D1��ʾ�ă�(n��i)�����o�ס�Ȼ��������Ȼ���ڣ���?y��n)?·ͨ��������������ͬ���|�l(f��)��������ͬ�ĕr(sh��)��l���M(j��n)�вɘӡ� �F(xi��n)���҂�������������DAQ��NI LabVIEW FPGA������(sh��)�F(xi��n)�ĸ��ͨ���ɘӡ�
�����D4. ͨ�^����DAQ��(sh��)�F(xi��n)���|�l(f��)ʽͬ��ģ�Mݔ��
�����D4���ψD��չ�F(xi��n)�ˣ���λ���ģ�Mݔ��ͨ��0�е�ģ�M�|�l(f��)������(du��)2·��ͬ��ģ�Mݔ��ͨ���M(j��n)��ͬ���ɘӡ���������DAQ�O(sh��)������Ъ�(d��)����ADC����ͬһI/O��(ji��)�c(di��n)�е�2·ͨ��������ȫ��ͬ�ĕr(sh��)�̽��ܲɘӡ� ���͵Ķ��DAQ�O(sh��)���ͨ�^һ��(g��)ADC��·��(f��)������ͨ������ˣ���·ͨ����횹�����ͬ�IJɘӕr(sh��)犺��|�l(f��)���� �D5���D��չ�F(xi��n)�ˣ�����DAQӲ���䌍(sh��)�܉��Ԫ�(d��)�������ʣ���(du��)��ͬ��ģ�Mݔ��ͨ���M(j��n)�вɘӡ� �ڪ�(d��)����·�з���ģ�Mݔ��I/O��(ji��)�c(di��n)��ÿ·ͨ����(hu��)����ȫ��ͬ�������M(j��n)�вɘӣ�Ȼ�����ͨ�^2�lDMAͨ���x��Ӳ�P��
�����D5. ͨ�^����DAQ��(sh��)�F(xi��n)���|�l(f��)ʽ������ģ�Mݔ��
���������ָ�����ǣ��҂�?n��i)���ϣ�?·ͨ���������(d��)���IJɘ��ʺ��_ʼ�|�l(f��)���t�Ʌ���?q��ng)D6��������I/O��(ji��)�c(di��n)�������ڲ���ѭ�h(hu��n)�Y(ji��)��(g��u)�С�ԓ��ʽ���������FPGA�IJ����ԣ��_���˸��(xi��ng)�΄�(w��)�܉�ʹ�Ì����YԴ���ڈ�(zh��)�Еr(sh��)��ȫ��(d��)���������ɼ��΄�(w��)��
�����D6. ͨ�^����DAQ��(sh��)�F(xi��n)�Ī�(d��)���|�l(f��)ʽ������ģ�Mݔ��
����ͬ��
����DAQmx�(q��)��(d��ng)�����ṩ��Nͬ���x��������ݔ���ݔ���ĕr(sh��)�g���P(gu��n)�ԡ� ���·��ij����D�У�ģ�Mݔ��ͨ����ģ�Mݔ��ͨ��������(sh��)���|�l(f��)��(sh��)�F(xi��n)ͬ�����^���У��茦(du��)ģ�Mݔ��ָ����(sh��)���|�l(f��)����ʹ��ģ�Mݔ����|�l(f��)����̖(h��o)�|�l(f��)�a(ch��n)��ģ�Mݔ����
�����D7. ͨ�^NI-DAQmx��(sh��)�F(xi��n)��ͬ��ģ�Mݔ���ݔ��
�����Ñ���ͨ�^����DAQӲ���p�����e�؈�(zh��)��ͬ���΄�(w��)�����o������΄�(w��)ID�Ͱ��d��̖(h��o)·�ɡ� ��̎���@ʾ��NI LabVIEW FPGA�еă�(n��i)�ݡ�
�����D8. ͨ�^����DAQ��(sh��)�F(xi��n)��ͬ��ģ�Mݔ���ݔ��
������̎���҂�?c��)ٴ�ͨ�^�l���Y(ji��)��(g��u)��FPGAоƬ�ψ�(zh��)��Ӳ���|�l(f��)������(sh��)��ͨ��0�ϵ������t��������l���еĴ��a�� �����Y(ji��)��(g��u)�У�ģ�Mݔ���cݔ���Ĺ�(ji��)�c(di��n)��ͬ�r(sh��)�����{(di��o)�õ��^���У����]���κζ���(d��ng)�����҂�ֻҪ��(ji��n)�ε��ڸ���(g��)��(d��)����Whileѭ�h(hu��n)��(n��i)Ƕ��ģ�MI/O��(ji��)�c(di��n)������������Ъ�(d��)���IJɘ����ʡ� ����ֵ��ע����ǣ� �����D���@ʾ�������l(f��)��������(sh��)��1��(g��)Express VI���Ɏ����Ñ��ڲ��ұ�(LUT)�н���ʽ����������ֵ��
�����D8�е�����DAQ�����D�c�D7�е�DAQmx VI�Ծ�����ͬ�Ĺ��ܣ���Ψ������DAQ���ܞ��Զ��x�΄�(w��)�ṩ����(y��ng)���`���ԡ� �e�����C����������1��(g��)��ͣ�|�l(f��)���҂�ֻ���ڃ�(n��i)��Whileѭ�h(hu��n)������1��(g��)�l���Y(ji��)��(g��u)����ͨ�^��һ��(g��)��(sh��)��I/O��(ji��)�c(di��n)�x����l����ٗl���������p������΄�(w��)�� ��(du��)Ӳ���M(j��n)�о��̵ď�(qi��ng)���ܣ���(sh��)�F(xi��n)�˸��I/O�Ķ��r(sh��)�cͬ����
�������ͬ������һ���C�w�F(xi��n)�飺ͨ�^���dӋ(j��)��(sh��)���a(ch��n)�������}�_����Ӌ(j��)��(sh��)��ݔ������ģ�Mݔ��IJɘӕr(sh��)犡� ԓ�^�����M(j��n)�п����|�l(f��)ʽ���ɘӵij����ֶΡ� �D�@ʾ���_չ��ɼ��������DAQmx���a��
�����D9. ͨ�^NI-DAQmx��(sh��)�F(xi��n)�Ŀ����|�l(f��)ʽ����ģ�Mݔ��
�����F(xi��n)�ڣ��҂���(du��)�D��(n��i)�ݺͳʬF(xi��n)��ͬ���ܵ�NI LabVIEW FPGA�����D�����Ա��^��
�����D10. ͨ�^����DAQ��NI LabVIEW FPGA��(sh��)�F(xi��n)�Ŀ����|�l(f��)ʽ����ģ�Mݔ��
��������NI LabVIEW���a��Ӳ�����\(y��n)�У��D10�е��(q��)��(d��ng)���ò��E�@Ȼ�õ��˘O�p�� �҂��ѽ�(j��ng)������(ji��n)�εĔ�(sh��)��ݔ�뾀��Forѭ�h(hu��n)�Y(ji��)��(g��u)����(chu��ng)����Ӳ�������|�l(f��)ʽ���ɼ��� �D9�еij����Dʹ��2��(g��)���dӋ(j��)��(sh��)������(chu��ng)���������|�l(f��)�������}�_���У����͵Ķ��DAQ�O(sh��)��ֻ��2��(g��)Ӌ(j��)��(sh��)���� ������NI LabVIEW FPGA������DAQӲ���s�܉�?q��)�����һ�l��(sh��)�־����ó�Ӌ(j��)��(sh��)���� �҂�����֮��Ķ�����漰���ࡰͨ�^����DAQ�\(y��n)��Ӌ(j��)��(sh��)��/���r(sh��)�����ă�(n��i)�ݡ�
�����҂��܉�������l���|�l(f��)�IJɼ����M(j��n)һ�������M(j��n)����DAQ��Ӳ�����r(sh��)������`�������ԡ� �Ñ���ͨ�^���ٰ��d�Q��Ӌ(j��)��ݔ����̖(h��o)���l�ʣ������x��l���Y(ji��)��(g��u)������Ĵ��a���@һ�c(di��n)��ʹ�õ��Ͷ��DAQ�O(sh��)�����o���ġ� �ڶ��O(sh��)���ͬ���M(j��n)���У�����DAQ߀���ṩ����PCI�忨��RTSI������������PXIģ�K��PXI�|�l(f��)������ �@Щ�ⲿ���r(sh��)��ͬ����߀��ͨ�^�����D�ϵ�I/O��(ji��)�c(di��n)�����L����
����ģ�M���ε�����
�������ٶ��DAQ�O(sh��)�䶼����ģ�Mݔ��ͨ�����܉�?y��n)��������B�m(x��)��ģ�M���ζ���Ҫ�õ�FIFO���_�� ���ɵIJ��οɌ�FIFO����ѭ�h(hu��n)���_�^(q��)���ҟo������C(j��)̎�����κθ���(sh��)��(j��)�������B�m(x��)�������������һϵ�е�ģ�Mֵ�� ͨ�ſ������Пo��(du��)��Ӱ푲�����?y��n)鲢�]��ᘌ�(du��)�O(sh��)����l����(sh��)��(j��)�x���� �����������Ҫ�ģ��ͱ��������(d��ng)ݔ���΄�(w��)����FIFO������(sh��)��(j��)�� ��һ��(g��)�k������Ӳ��FIFO�O(sh��)���B�m(x��)�x����(sh��)��(j��)�����@�֕�(hu��)��(d��o)��ݔ���΄�(w��)���F(xi��n)�r(sh��)���� ��������DAQ���Ñ��܉�?q��)�����ݔ���Y(ji��)���惦(ch��)��Ӳ���������܉�ͨ�^Ӳ���|�l(f��)��׃���Σ��M(j��n)����(chu��ng)�����Ⲩ�ΰl(f��)������
�����·��ĺ���(sh��)�l(f��)��������ͨ�^��(sh��)��ݔ�뾀���|�l(f��)��ݔ�������еĸĄ�(d��ng)�� ͨ�^�M�ϔ�(sh��)��I/O��0�c1���҂�?n��i)����ˑ?y��ng)����ģ�Mݔ����4�N��ͬ��B(t��i)��Q�l����
�����D11a. ��������DAQ�l��0�ĺ���(sh��)�l(f��)���� �C ��ݔ��
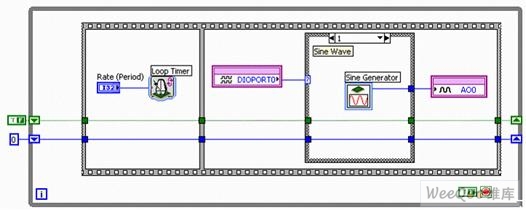
�����D11b. ��������DAQ�l��1�ĺ���(sh��)�l(f��)���� �C ���Ҳ�
������(d��ng)�ɾ��ԳʬF(xi��n)���ƽ�r(sh��)����(zh��)�Зl��0����D11a��ʾ��ݔ��ֵ��0 V����������(d��ng)DIO��0�ʬF(xi��n)���ƽ��DIO��1�ʬF(xi��n)���ƽ�r(sh��)���l��1����ģ�Mݔ��0�ψ�(zh��)�в�����һ��(g��)���Ҳ����Ñ���ͨ�^ԓ�������ɽY(ji��)��(g��u)���D11b���е����Ұl(f��)����Express VI������NI LabVIEW FPGA����ą���(sh��)���������������Ҳ���
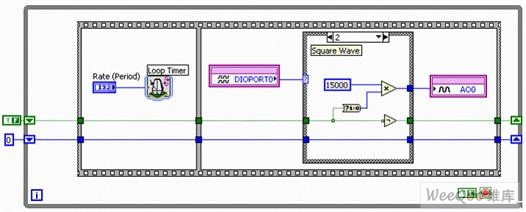
�����D11c. ��������DAQ�l��2���(sh��)�l(f��)���� �C ����
�����l��2���D11c���܉���Whileѭ�h(hu��n)��ÿ݆�����У��p���ГQ����ֵ�� ��(sh��)ֵ�^�͕r(sh��)������(sh��)15000�㱻����ģ�Mݔ��AO0���Ԍ�(du��)��(y��ng)16λDAC��(n��i)��ݔ���Ĵ�����ŵĔ�(sh��)ֵ��15000�� 16λ�з�̖(h��o)����(sh��)������-32768��32767֮�g�Ĕ�(sh��)ֵ����(d��ng)ݔ��늉���������-10 V��10 V�r(sh��)����ģ�Mݔ��AO0����-32768��(hu��)����-10 V늉���������32767�t����10 V늉���ԓ���У����҂��Č���ֵ��15000���t���ɵ�늉�������5 V������(sh��)�W(xu��)��ʽ��: 15000/32767 * 10 V = 4.5778 V�� ͨ�����l��2��(hu��)ݔ��һ��(g��)��0 V��4.578 V֮�g׃�Q�ķ�����
�����D11d. ��������DAQ�l��3���(sh��)�l(f��)���� �C ��X��
������(d��ng)DIO 0��DIO 1���ʬF(xi��n)���ƽ�r(sh��)�����(zh��)�����һ��(g��)�l�����D11d�������g��횽������ұ�(LUT)�B�m(x��)����һ��(g��)��X���� ������һ�Express VI�IJ��VI�����ܴ惦(ch��)���Ⲩ��ֵ��Ҳ��ͨ�^���̽�������ֵ�������� ԓ���У��������õ���X������ģ�Mݔ��ͨ��0�����ɡ�
����ͨ�^�����е�ֵ���惦(ch��)��FPGA�ϣ��Ñ��ڽ��Ϳ�����ه�Ե�ͬ�r(sh��)��Ҳ�_���˲��θ��r(sh��)Ӳ�����r(sh��)���ٶȺͿɿ��ԡ� ֮ǰ����������������ģ�Mݔ����|�l(f��)��ͬ���`����ͬ���m����ģ�Mݔ������������DAQ���Ñ��܉��Բ�ͬ���ʣ���ȫ��(d��)���ظ��¸�·ģ�Mݔ��ͨ���� �@��ζ�����Ñ����ڲ�Ӱ�����ͨ��ݔ���Y(ji��)����ǰ���£��Ć�(g��)�����Բ��ε��l�ʡ� Ո(q��ng)ע�⣺�����(sh��)��(sh��)��(j��)�ɼ�Ӳ�������߂���(xi��ng)���ܡ�
����Ӌ(j��)��(sh��)��/���r(sh��)���IJ���
������ǰ���������͵Ķ��DAQ�O(sh��)��ֻ��2��(g��)���dӋ(j��)��(sh��)����������DAQ�t���ڸ��l��(sh��)�־����\(y��n)��Ӌ(j��)��(sh��)�����ܡ� ��(sh��)��I/O��(ji��)�c(di��n)�܉���NI LabVIEW FPGA��������������ڶ��r(sh��)ѭ�h(hu��n)�Č��I(y��)�Y(ji��)��(g��u)�������Ñ���2.5 MHz��200 MHz���ض��l�ʷ�����(n��i)��(zh��)�д��a�� ���磬����40 MHz�ĕr(sh��)犣��Ñ���ʹ�Æ����ڶ��r(sh��)ѭ�h(hu��n)���ڸ��l��(sh��)�־��τ�(chu��ng)��40 MHzӋ(j��)��(sh��)���� �D12���D��չ�F(xi��n)�˳����D�Ę�ʽ��
�����D12. ��������DAQ�ĺ�(ji��n)���¼�Ӌ(j��)��(sh��)��
��������Ӌ(j��)��ֵ����U32��32λ����(sh��)���Ĕ�(sh��)��(j��)��ͱ��l(f��)�����@ʾ�ؼ���ԓ���a����FPGAоƬ��������1��(g��)40 MHz��32λӋ(j��)��(sh��)���� �Ñ��Ɍ�(du��)���M(j��n)�Д�(sh��)�Ώ�(f��)���cճ�N���ͬ��(sh��)�־��ϵĶ���(g��)Ӌ(j��)��(sh��)�����܉�˴���ȫ���е��\(y��n)�С� ͨ�^��(du��)����DAQ�Ѕ���(sh��)���O(sh��)�ÿ��Ԍ�(sh��)�F(xi��n)���r(sh��)���������Զ��x�� ͨ�^�x���Ñ��܉�ÿ��2��(g��)�����ر��M(j��n)��1��Ӌ(j��)��(sh��)���f���������ܻ���Ӌ(j��)��(sh��)�Ĵ�����ֵ�|�l(f��)ģ�M�ɼ��� �S����(f��)�s��Ӌ(j��)��(sh��)���������磺�����}�_�������ɺͼ�(j��)(li��n)ʽ�¼�Ӌ(j��)��(sh��)������Ҫʹ��2��(g��)Ӌ(j��)��(sh��)�����@��ζ��ʹ�õ��Ͷ���O(sh��)���е����а��dӋ(j��)��(sh��)���� �ڿ���160�l��(sh��)�־��Ď����£�����DAQӲ���϶��r(sh��)�������(sh��)�������ܵ�I/O�����Ե�Ӱ푣�������ȡ�Q��FPGAоƬ�Ĵ�С�� ����NI LabVIEW���a�\(y��n)���ڹ�оƬ�У�����Ñ��o�衰�b�䡱�������b�䡱ͨ��Ӌ(j��)��(sh��)��������ȫ�����Ӌ(j��)��(sh��)�����\(y��n)�С�
�����D13���D���еķ���ʹ��Ӌ(j��)��(sh��)����������һ��(g��)�B�m(x��)�}�_���в�����ͣ�|�l(f��)������NI-DAQmx�С�
�����D13. �B�m(x��)�}�_���е����ɺ�����NI-DAQmx�ĕ�ͣ�|�l(f��)��
������NI LabVIEW FPGA�У���ͣ�|�l(f��)���o��������ã���?y��n)�ֻ��?ji��n)�εėl���Y(ji��)��(g��u)�����ڹ�оƬ�Ќ�(sh��)�F(xi��n)��ͬ�Ĺ��ܡ� ��̎��ͨ�^����DAQ�\(y��n)�Еr(sh��)��չ�F(xi��n)����ͬ���ܣ��D14����
�����D14. �B�m(x��)�}�_���е����ɺ���������DAQ�ĕ�ͣ�|�l(f��)��
�������@�N��r�£���(sh��)��I/O��DIO0������ͣ�|�l(f��)�����}�_���ڔ�(sh��)��I/O��DIO1�����ɲ�ݔ����ʹ�Æ����ڶ��r(sh��)ѭ�h(hu��n)�������(g��)�}�_�@��25 ns�ķֱ��ʣ���?y��n)��@���ɞ��(g��)Ӌ(j��)�r(sh��)��ʹ��40 MHz���r(sh��)Դ�r(sh��)��ֵ��
������(sh��)��I/O��(y��ng)��
��������DAQӲ���ṩ���_(d��)160�lӲ�����r(sh��)��(sh��)�־������T����(sh��)�֑�(y��ng)�óɞ���ܡ� �҂��ѽ�(j��ng)�W(xu��)��(x��)�����ʹ�Ô�(sh��)��I/O��(sh��)�F(xi��n)�|�l(f��)��ͬ����Ӌ(j��)��(sh��)��/���r(sh��)�����\(y��n)�У�������DAQ߀�������`�a�ʜy(c��)ԇ����(sh��)��ģʽƥ�䡢�}�_�����{(di��o)�ơ��������a���͔�(sh��)��ͨ�Ņf(xi��)�h�� �Զ��x���(bi��o)��(zh��n)��ʽ�Ĵ��нӿھ���ֱ��ͨ�^��(sh��)�ֶ��r(sh��)��D���́팍(sh��)�F(xi��n)�� �e���f����SPI����һ���cӲ���M�����磺��������ADC���M(j��n)��ͨ�ŕr(sh��)��õ������f(xi��)�h�� �D15���D��չ�F(xi��n)�����M(j��n)��16λSPIͨ�ŕr(sh��)��3�l��Ҫ��(sh��)�־�����(du��)��(y��ng)�Ķ��r(sh��)��D��

�����D15. SPIͨ��ݔ�붨�r(sh��)��D
�����綨�r(sh��)��D��ʾ������16λ��(sh��)��(j��)����ÿ��(g��)�r(sh��)�������혴��f����Ƭ�x���ƾ���chip select line)�t�ʬF(xi��n)���ƽ�� �F(xi��n)�ڣ��҂���������NI LabVIEW FPGA�У����ͨ�^����DAQӲ���ϵ�3�l��(sh��)�־��M(j��n)�д���̡�
���^ȥ�İ낀(g��)���o(j��)������·���g(sh��)���M(j��n)������ˢ����ȫ�������Ϣ�a(ch��n)�I(y��)���ΑB(t��i)�����ʮɫ���®a(ch��n)Ʒ����(y��ng)��Ҳ��׃��������ʽ��Ȼ�������¼��g(sh��)�����ġ��˵����M(f��i)��Խ��Խ��ϲ� ��f������Ӯa(ch��n)Ʒ���Ј�(ch��ng)������������s�̣�����I(y��)��(du��)�ڮa(ch��n)Ʒ����IJ�и�����M(j��n)һ�����s�ˆ�(g��)�a(ch��n)Ʒ���Ј�(ch��ng)���g���c��ͬ�r(sh��)����ˇ���g(sh��)������(j��)Ҳ�a(ch��n)Ʒ���_�l(f��)�ɱ��ʎμ�(j��)��(sh��)�������Ј�(ch��ng)�ں�һ�N�܉��аl(f��)�ɱ����s���_�l(f��)���ڲ������O(sh��)Ӌ(j��)�`���ԵĮa(ch��n)Ʒ���ڴ˱����£�F(xi��n)PGA(�F(xi��n)��(ch��ng)�ɾ����T���)�a(ch��n)�I(y��)��u�Ѵ��@¶����������Ě��(sh��)��
������ʳASIC/ASSP�Ј�(ch��ng)
�����аl(f��)�ɱ�������̧����ASIC(���ü����·)��ASSP(���Ø�(bi��o)��(zh��n)�·)���аl(f��)�T�����{(di��o)�ЙC(j��)��(g��u)IBS�ṩ�Ĕ�(sh��)��(j��)�@ʾ���ڼ����·��90�{��(ji��)�c(di��n)�����аl(f��)�ɱ��s��2000�f��Ԫ����65�{��(ji��)�c(di��n)�аl(f��)�ɱ��ѽӽ�4000�f��Ԫ��Ŀǰ�����M(j��n)��32�{��28�{��ˇ���g(sh��)���аl(f��)�ɱ���s��9700�f��Ԫ��������22�{��(ji��)�c(di��n)�����аl(f��)�ɱ��A(y��)Ӌ(j��)��ͻ��1.5�|��Ԫ��ͨ���������·�O(sh��)Ӌ(j��)��I(y��)ᘌ�(du��)ij�N�a(ch��n)Ʒ���аl(f��)�ɱ��cԓ�a(ch��n)Ʒ���N������֮�Ȟ�1��5��Ҳ�����f����(d��ng)�O(sh��)Ӌ(j��)�M(j��n)��32�{��/28�{��֮����I(y��)ֻ���ڌ�(du��)��a(ch��n)Ʒ���N���A(y��)�ڴ���5�|��Ԫ��ǰ��֮�²ŕ�(hu��)Ͷ���YԴ�M(j��n)���аl(f��)�����ü�˹�ˇ���g(sh��)��ASIC��ASSP��(sh��)�������ص�������V�Įa(ch��n)Ʒ�I(l��ng)����һЩ�Ј�(ch��ng)���g�^С�ļ�(x��)���I(l��ng)���҂��������������¼��g(sh��)��FPGA��ˇˮƽ����(du��)�^�͵�ASIC/ASSP�M(j��n)���^����
���������g(sh��)���M(j��n)����FPGA����(sh��)���ɓ�����ԭ��(d��ng)������ِ�`˼��˾��̫�^(q��)�N���c�Ј�(ch��ng)�����×��w�ڽ��ܡ��Ї�(gu��)��ӈ�(b��o)��ӛ�߲��L�r(sh��)��ʾ��������(j��)�҂��Ľy(t��ng)Ӌ(j��)����90�{��ˇ��(ji��)�c(di��n)��ASIC��ASSPֻ�в���25%�ġ����y(t��ng)�I(l��ng)�ء���(hu��)�ܵ�FPGA������(zh��n)����������28�{��ˇ֮��ASIC��ASSP���г��^75%�đ�(y��ng)���I(l��ng)�����RFPGA�ĸ�(j��ng)��(zh��ng)�����H��ˣ�F(xi��n)PGA߀���������ă�(y��u)��(sh��)���ڟo��ͨ�š�����ҕ�l�O(ji��n)�صȶ���(g��)�I(l��ng)���Q�˂��y(t��ng)ASIC��ASSP��DSP�����o����Q�Ć��}����
�����Ј�(ch��ng)�{(di��o)�ЙC(j��)��(g��u)Gartner�ṩ�Ĕ�(sh��)��(j��)�ƺ�ӡ�C�˗��w���^�c(di��n)����1998���ԁ���ȫ��ASIC�����(xi��ng)Ŀ��(sh��)�������f�p��2009��Ľ��������_(d��)��21.7%��ASSP��r�Ժã��������(xi��ng)Ŀ��(sh��)����2005���ԁ������f�p���A(y��)Ӌ(j��)��2013�꣬�����(xi��ng)Ŀ��(sh��)����2004���4762�(xi��ng)�p�ٞ�3262�(xi��ng)����(d��ng)Ȼ��ֵ��һ����ǣ�ASSP�����w�Ј�(ch��ng)���ڿ������L(zh��ng)��
��������(d��ng)Ȼ���ڂ��y(t��ng)�����M(f��i)�����ИI(y��)��ASIC�a(ch��n)�����н^��(du��)�ĵͳɱ���(y��u)��(sh��)��ռ��(j��)�˺ܴ���Ј�(ch��ng)���~�������ڹ��I(y��)�I(l��ng)���������(y��ng)�÷��棬���ڿɾ���߉�����Ľ�Q�������^�m(x��)������Ҫ��ɫ����Altera��˾��̫�^(q��)��(j��)�Ј�(ch��ng)��(j��ng)���_���[��ʾ�����������ASIC�ijɱ��ڲ����������҂��ѽ�(j��ng)�I(l��ng)����ASIC�ИI(y��)���e����40�{��(ji��)�c(di��n)���҂��A�õĴ��O(sh��)Ӌ(j��)��(sh��)�H�ρ���Altera����Ҫ�Ñ���Ҳ�����f������?c��)�һֱʹ�ø?j��ng)��(zh��ng)��(du��)�ֵ�FPGA��Q������������ASIC��ASSP��DSP����
������չ��δ�����ɾ���߉�Ј�(ch��ng)ǰ��һƬ��������ِ�`˼��˾���ü�CEO Moshe Gavrielov��ʾ������(j��)�������A(y��)�y(c��)��2010�꣬ԓ�ИI(y��)���Ј�(ch��ng)���L(zh��ng)�ʌ���45%���ϣ��_(d��)��48�|��Ԫ��������(j��)Raymond James Financial��˾�ṩ�Ĕ�(sh��)��(j��)���ɾ���߉�Ј�(ch��ng)����ȡԭ�Ȍ���ASICꇠI(y��ng)��150�|��Ԫ��200�|��Ԫ���Ј�(ch��ng)���~���� 
���������¡������c(di��n)��
�����mȻFPGA�ИI(y��)�����w�l(f��)չ�ٶȸ���ASIC/ASSP������(du��)��FPGA�ďĘI(y��)�߁��f����θ�������˽��O(sh��)Ӌ(j��)�ˆT������ͨ�^�a(ch��n)Ʒ��(chu��ng)��FPGA�����µ��Ј�(ch��ng)�������c(di��n)����������һֱ�����R������(zh��n)��
������2010�꣬F(xi��n)PGA�a(ch��n)�I(y��)�����˲�Ŀ�İl(f��)չ�C(j��)���ǝM��Խ��Խ�ߵĎ�����������ǰ�H����ASIC��ASSP�đ�(y��ng)����ʹ��FPGA����Altera��˾��(j��)�Ј�(ch��ng)������Danny Biran�����f������(gu��)�����P(gu��n)�C(j��)��(g��u)�A(y��)�y(c��)����2015�꣬����(gu��)IP����ÿ�ꌢ�_(d��)�����ֹ�(ji��)(1021�ֹ�(ji��))����Ӌ(j��)�㡢ҕ�l�Α�VoIP��ҕ�l�c(di��n)���ȑ�(y��ng)���Ƅ�(d��ng)�ˎ�����������L(zh��ng)����ˣ�ϵ�y(t��ng)�_�l(f��)�ˆT��Ҫ���и����հl(f��)����Ӳ�������@���棬���µ�FPGAҪ������Ӳ����Q�������߃�(y��u)��(sh��)��
������?y��n)�ASIC��ASSP��Ƭ�r(sh��)���H�հl(f��)����IP�M(f��i)�þ��_(d��)��ʮ�f��Ԫ������Ҫ�f���M(j��n)��ˇ��(ji��)�c(di��n)����Ƭ�r(sh��)�M(f��i)�õĿ����������T���L(f��ng)�U(xi��n)�ˡ�
�������ң����H�H��ͨ���Ј�(ch��ng)��(du��)�����հl(f��)��������2010����(li��n)�W(w��ng)�Ĺ��I(y��)�Ԅ�(d��ng)���Ј�(ch��ng)Ҳ�������������I(y��)��̫�W(w��ng)��ϵ�y(t��ng)�����S�o(h��)���������¡��@Ҳ��һ���ǰ���]��ʹ��FPGA�đ�(y��ng)�á����ڹ��I(y��)�I(l��ng)�����̫�W(w��ng)��(bi��o)��(zh��n)�N��ֻ࣬�в���FPGA���Ñ�����ᘌ�(du��)��ё�(y��ng)��ʹ�ú��m�ąf(xi��)�h���@Ȼ��F(xi��n)PGA���@�(y��ng)�Î�������ԃr(ji��)�ȡ�
����ͬ�r(sh��)���Ї�(gu��)��2010��������M(j��n)���W(w��ng)�ںϣ�F(xi��n)PGA�ИI(y��)��ʿҲ�c���W(w��ng)�ںϸ��h(hu��n)��(ji��)�O(sh��)����I(y��)��ͬ����������ͨ�Ž�Q���������ܶ�EdgeQAM��Q������ҕ�l�߶����lƽ�_(t��i)�������I(l��ng)��?q��)����µęC(j��)������һЩ�h(hu��n)��(ji��)���Dz���FPGA߀��ASIC��ASSP���O(sh��)����I(y��)�Пo��Փ��F(xi��n)PGA��I(y��)���ڃ�(y��u)��FPGA�������ԃr(ji��)�ȣ������A(y��)Ҋ�����W(w��ng)�ں��Ј�(ch��ng)�ϵĠ�(zh��ng)�Z��(zh��n)�ѽ�(j��ng)��푡�ͬ�������Ј�(ch��ng)һ�ӣ������W(w��ng)�ں��Ј�(ch��ng)��F(xi��n)PGA�a(ch��n)�I(y��)ͬ�����R�����Ӗ(x��n)���̎�������(zh��n)�����@�N�ں�څ��(sh��)�£��S����(sh��)�ֹ��̎�������W(xu��)��(x��)���l�I(l��ng)��ĸ��l�O(sh��)Ӌ(j��)���g(sh��)�������ع�˾��(j��)�a(ch��n)Ʒ�Ј�(ch��ng)�ƏV��(j��ng)��Rajiv Nema�f��
�������⣬�ڸ߶�ҕ�l�O(ji��n)���Ј�(ch��ng)��1080p��������ܸ�ۙ�Լ�������(du��)��(sh��)��(j��)̎���������������һЩ�����У�DSPƽ�_(t��i)�џo��֧�Σ���ˣ�һЩ�߶˱O(ji��n)��ƽ�_(t��i)���D(zhu��n)��FPGA�IJ���̎�����g(sh��)��
�������M(f��i)ic37���^ȥ������FPGA�ă�(y��u)��(sh��)�I(l��ng)���ǣ����һ����Ҳ�l(f��)�����@�˵��D(zhu��n)׃������(du��)���M(f��i)���Ӯa(ch��n)Ʒ���ԣ����ȰѮa(ch��n)Ʒ�����Ј�(ch��ng)����ζ�����Դ_���Ј�(ch��ng)��(y��u)��(sh��)�����@�ø��ߵ�����(r��n)����ِ�`˼��˾��̫�^(q��)�N���c�Ј�(ch��ng)�����×��w��B�f����FPGA�c��������`����ǡǡӭ���˿s���������ڵ�������ˣ��҂�����Խ��Խ���ƽ���ҕ���֙C(j��)�����M(f��i)���Ӯa(ch��n)Ʒ���ڴ���ʹ��FPGA������(d��ng)Ȼ���@�cFPGA�ڹ��ġ��ɱ��ͳߴ��ϵĄ�(chu��ng)�º����оo��(li��n)ϵ���@Щ�����ڽY(ji��)��FPGA��Ȼ�ă�(y��u)��(sh��)�������M(f��i)����O(sh��)Ӌ(j��)�ˆT�ṩ���ԃr(ji��)�ȸ��ߵķ����������������h(yu��n)�Ƽ�����˾Actel FPGA�Ј�(ch��ng)�ƏV�c���g(sh��)֧�ֹ��̎����������e����B�f��F(xi��n)PGA�����ijߴ��ѽ�(j��ng)С��3mm��3mm�������N���֙C(j��)�������c��Ļ֮�g���ž����棬��(j��ng)�^FPGA�ӿ��D(zhu��n)�Q��TFT�r(sh��)��[Ó��ԭ���֙C(j��)��Ļ�����ƣ��F(xi��n)���֙C(j��)����ʹ��һ��(g��)�κνӿژ�(bi��o)��(zh��n)����Ļ�ˡ����ǵ�һ���ǰ���p��Ļ�Ĕ�(sh��)�a���C(j��)���O(sh��)Ӌ(j��)�д�đ����FPGA�����������Ӱ��s����ǰ��С���ϡ��������ǵ��I(l��ng)�^����I(y��)�����I(l��ng)�������M(f��i)���ϵ�y(t��ng)�O(sh��)Ӌ(j��)��I(y��)����FPGA��
��������ܛ�����̎�
�������ˌ����Ј�(ch��ng)�ϵġ������c(di��n)���⣬F(xi��n)PGA�ИI(y��)Ҳ����ԇ�Dͨ�^��׃�����Įa(ch��n)Ʒ���Ժ��O(sh��)Ӌ(j��)���́����������ϵ�y(t��ng)�O(sh��)Ӌ(j��)���̎���������;��֮һ��������ARM������ARM��FPGA�ИI(y��)����ɴ����@���D(zhu��n)׃��һ��ʹFPGAƽ�_(t��i)�ɞ��^���_�š��и�����(y��ng)�ð����������̎�����Ϥ��SoC�_�l(f��)ƽ�_(t��i)������FPGA���O(sh��)Ӌ(j��)���̏���Ӳ���O(sh��)Ӌ(j��)�����D(zhu��n)׃?y��u)���ܛ���������@�ɴ��D(zhu��n)׃�o�Ɍ����������ϵ�y(t��ng)�O(sh��)Ӌ(j��)���̎��e��ܛ�����̎���(y��ng)��FPGA��
�������ع�˾ȫ����ϯ��(zh��)�й�John East�����f��������Ƕȁ�����ϵ�y(t��ng)�O(sh��)Ӌ(j��)���̎�������Ҫ����һ��(g��)�ɶ��ƻ��Ľ�Q�����������(sh��)ϵ�y(t��ng)�O(sh��)Ӌ(j��)�ˆT������ǰ�_��̎������(n��i)�ˣ�����(du��)���������ֵ�Ҫ��ֱ���O(sh��)Ӌ(j��)���ڵ����һ��状����ܸ�׃����ˣ����O(sh��)Ӌ(j��)�ˆT���ڴ����@ôһ��(g��)��Q������������Ƕ��ʽ�I(y��)���(bi��o)��(zh��n)��(n��i)�ˣ�����ֱ�^���õ��O(sh��)Ӌ(j��)���̣��܉��(zh��)�����x���O(sh��)�Ľ�(j��ng)ȫ���(y��n)�C��IP�M���Լ�һ��(g��)�ɘI(y��)���I(l��ng)�ȹ��߽M�ɵ����B(t��i)ϵ�y(t��ng)�����߀���c����B�ӵ�Ƭ�Ͽɾ���ģ�M���ܡ�������ᘌ�(du��)�@�ӵ������O(sh��)Ӌ(j��)�Ƴ��˼���ARM Cortex M3��SmartFusion��оƬ�������J(r��n)�飬�ܿ�أ�SoC�͌��ɞ��O(sh��)Ӌ(j��)�����c(di��n)�������ǽK�c(di��n)����John East�f��
����ِ�`˼��˾��̫�^(q��)�Ј�(ch��ng)����(y��ng)�ÿ��O(ji��n)������t��ʾ��ِ�`˼��ARM Cortex-A9����FPGA��������һ��(g��)����̎������������FPGA���o����ϵ�y(t��ng)������̎��������ĵ��O(sh��)Ӌ(j��)��������֧��һ��(g��)��ܛ������ĵ��_�l(f��)���̡�
��������ȫ������ܛ�����̎��cӲ�����̎���(sh��)��֮�ȳ��^��10��1������ϵ�y(t��ng)�O(sh��)Ӌ(j��)�Ĺ�������80%������ܛ���_�l(f��)����ˣ�10�����F(xi��n)PGA�S��һֱ�ڌ���ѱ����Ƕ��ʽܛ�����̎����뵽��Ҫ��Ӳ���O(sh��)Ӌ(j��)���̎���(g��u)�ɵ��Ñ�Ⱥ�w�С���ARM��˾Ƕ��ʽ��(y��ng)���Ј�(ch��ng)��(j��ng)���_�،�(du��)���Ї�(gu��)��ӈ�(b��o)��ӛ���f�����M(j��n)һ�������f����ǰ����FPGA�����_�l(f��)ƽ�_(t��i)���O(sh��)Ӌ(j��)����һ����Ҫ���_�l(f��)Ӳ����Ȼ�����_�l(f��)ܛ��������ARM����FPGA��ϵ�y(t��ng)�O(sh��)Ӌ(j��)�����ȏ�ܛ���_�l(f��)�ĽǶȁ����x�a(ch��n)Ʒ���ܺ�ģ�K����Щ������Ҫܛ�����_�l(f��)ܛ������Щ������Ҫʹ��FPGA��������Ӳ���_�l(f��)�����@�N��̎��������ĵ�ϵ�y(t��ng)���x���O(sh��)Ӌ(j��)��������֧��һ��(g��)��ܛ������ĵ��_�l(f��)���̡����_���f�����@�ӣ�ܛ�����̎���(hu��)Խ��Խ��ر����뵽�(xi��ng)Ŀ�Ё�����������ܛ�����̎��Ñ�Ⱥ�w���o�Ɍ���չFPGA���Ј�(ch��ng)�I(l��ng)�ء�
| ����(n��i)�ݺ��_��,����܌�(d��o)����治�����Ĵ��a |
|---|
| �f���������@ʾ���Ǵ��a��(n��i)�ݡ��������șz���^���a�]���}������֮�����\(y��n)��. |
���ٹ��I(y��)���������ţ�2005������ȡ��60%��PCI�ӿ��Ј�(ch��ng)��Ӣ�ؠ�Ҳ�A(y��)Ӌ(j��)�����PC���Pӛ����X������(w��)��������վ��ͨ�ź�Ƕ��ʽ�a(ch��n)Ʒ���V������PCI Express��������ȫ���Ƅ�(d��ng)��ƽ�_(t��i)�����ϵ��µ���PCI Express�Ŀ����w�ơ�
�@һ���g(sh��)�l(f��)չڅ��(sh��)Ҳ��(du��)FPGA����(y��ng)�̵İl(f��)չ��(zh��n)�Ԯa(ch��n)�����ஔ(d��ng)���Ӱ푡����磬Altera��(j��)�Ј�(ch��ng)������Jordan Plofsky������ܱ���ӛ�߲��L�r(sh��)��ʾ���������҂�����Stratix GX��Stratix II GX��CyClone II��HardCopy II�ṩPCI Express�ӿ�֧�֡����@��ζ��Altera����������Ñ��Ј�(ch��ng)�ṩPCI Express��(n��i)�ˡ�
 |
|
Plofsky: Altera���� |
��(sh��)�ϣ�Altera����ڞ�˷e�O������(zh��n)�䡣���ڽ�����·ݣ�Altera��PMC-Sierra��˾�����l(f��)����һ������Altera�ɾ���߉��PMC-Sierra�հl(f��)�����g(sh��)�ĸ��ٴ���I/O��Q�������@һ����ʹ��Altera�ͳɱ�CyClone II FPGA��Stratix II FPGA��HardCopy II�Y(ji��)��(g��u)��ASIC���Ñ��܉�ͨ�^PMC-Sierra PM8358 QuadPHY 10GX����/���(��SERDES�հl(f��)��)������ʹ�õ������o�p��ֲ�����ٴ��Ѕf(xi��)�hϵ�y(t��ng)�С��@һ�M�Ͻ�Q����ʹ���Ñ��܉�(y��ng)�Õr(sh��)�����еĸ��ٴ���ͨ�Ņf(xi��)�h(��PCI Express��Serial RapidIO��10G��̫�W(w��ng)�����wͨ����ͨ�Åf(xi��)�h�o���ӿڵ�)�팍(sh��)�F(xi��n)оƬ�g��PCB��֮�g�Լ�ϵ�y(t��ng)�g��ͨ���B�ӡ���(du��)��(x��)�T��FPGA/�հl(f��)���������Ñ���AlteraҲ�ṩ�˼���SERDES�Ľ�Q������
PMC-Sierra��˾�Ј�(ch��ng)���O(ji��n)Travis KarrҲ��(qi��ng)�{(di��o)����QuadPHY 10GX SERDES��Altera FPGA�ĽY(ji��)���܉�?y��n)��Ñ��ṩ��߳ɱ�Ч��Ľ�Q��������֧��������1.2��3.2Gbps֮�g����Ҫ���d���Ѕf(xi��)�h����
�����(sh��)�_(t��i)ʽPC�ͷ���(w��)������(y��ng)���A(y��)Ӌ(j��)�ڽ��ڌ�����PCI��PCI Express�ɷN��۲���ķ�ʽ��Ȼ����һ����������̭PCI��ۡ�PCI Express�ڹPӛ����X�еđ�(y��ng)��Ҳ�ڿ�������֮�С�
�Ј�(ch��ng)�о���˾Insight6??������Nathan Brookwood��ʾ��PCI Express��������һ��(g��)��̎���܉�?y��n)��Ñ��ṩ������`���ԡ�PCI������Ҫ�Ñ����_�C(j��)�������NӲ��������PCI Express�������SPC���C(j��)����(y��ng)��ֱ�Ӱ��B��߉�����������ϣ��Ñ�ֻ��Ҫ��(ji��n)�ε��ڙC(j��)�������뾀�|�Ϳ����ˡ�
��һ��ҪFPGA����(y��ng)��XilinxĿǰ�ѿ����Ñ��ṩPCI Express��(n��i)�ˣ���Virtex II Pro FPGA������RocketIO 3.125Gbps�հl(f��)������ȫ����֧�ֆ���ͨ�����ʞ�2.5Gbps�Ć�ͨ��PCI Express�ӿڵČ�(sh��)�F(xi��n)��
�S��FPGA�ɱ���ֱ���½�(Ŀǰ����˵�FPGA�r(ji��)���ѵ���3��Ԫ����)��F(xi��n)PGA��HardCopy II�Y(ji��)��(g��u)��ASICԽ��Խ��سɞ��_�l(f��)��СҎ(gu��)ģASIC��ASSP���Ñ��ĵ�һ�x��Plofsky¶��Ŀǰ����ICƷ�ƹ���(y��ng)���_ʼֱ�Ӳ����҂���Stratix II FPGA��HardCopy II�a(ch��n)Ʒ�_�l(f��)��ASSP��
Gartner��һ���Ј�(ch��ng)�о���(b��o)����Ҳָ������s65-70%�Ĕ�(sh��)��ASIC�O(sh��)Ӌ(j��)������HardCopy��HardCopy II����ɣ��@��ζ��HardCopy���Ј�(ch��ng)������2006���_(d��)��150�|��Ԫ��
ĿǰAltera�ܶ���ߵ�Stratix II FPGA�����_�l(f��)���220�f�T��ASIC�����f�TASIC�ijɱ���ֻ��15��Ԫ��HardCopy II�Y(ji��)��(g��u)��ASIC֧�ֵ���߹����l�ʞ�350MHz��
���(y��n)�C��Ŀǰ�Ї�(gu��)���̎����_�l(f��)���f�T����FPGA�r(sh��)����������g(sh��)����(zh��n)����Plofskyָ��������̖(h��o)�����Ժ�EMI/EMC���}Ҳ����Ҫ���O(sh��)Ӌ(j��)����(zh��n)�����䮔(d��ng)�����_�l(f��)��(f��)�s���ٵ�FPGA�O(sh��)Ӌ(j��)�r(sh��)����
2004��Altera��ɹ��Įa(ch��n)Ʒ��Cyclone����ȫ���\(y��n)���s�_(d��)����750�fƬ�����đ�(y��ng)���I(l��ng)���Ǹ��N��͵�TV����LCD��PDP TV���ځ�̫�Ј�(ch��ng)������Ҫ��(y��ng)�����ձ����n��(gu��)���_(t��i)���^(q��)�����M(f��i)��Ӯa(ch��n)Ʒ�У����yʽ��ý�w���řC(j��)�У���
Altera���Ї�(gu��)�^(q��)����(j��ng)���w���hҲ¶��Stratix�ѽ�(j��ng)���ձ����n��(gu��)����Ż��A(ch��)�O(sh��)ʩ�a(ch��n)Ʒ��(���վ)�M(j��n)���������l(f��)؛�A�Σ�Stratix IIĿǰҲ���И�(bi��o)�˲����O(sh��)Ӌ(j��)���A(y��)Ӌ(j��)�ڲ��õČ���Hardcopy IIҲ�����M(j��n)��������؛�A�Ρ�
]]>���d�ӿژ�(bi��o)��(zh��n)�C��
����鿴һ�µ���ͨ��ϵ�y(t��ng)�ĽY(ji��)��(g��u)�����Կ����ܶ�Ԫ������Ҫ��M(j��n)��ͨ�š���M�㔵(sh��)��(j��)ͨ���и��NԪ���IJ�ͬ����������F(xi��n)�˸��N��ͬ�Ľӿژ�(bi��o)��(zh��n)��Ҫ�˽���N�ӿڵă�(y��u)ȱ�c(di��n)������Ҫ�鿴Ԫ��������ÿ��(g��)Ԫ�����l(f��)����ͨ����͡��@��Ĺ�늽ӿ��_ʼ��Ȼ����һ��B��(n��i)��Ԫ����ֱ�����Q�ܘ�(g��u)��switch fabric��.
a.�c�������D(zhu��n)�Q�����B�������
�ڸ��ٹ��wͨ��ϵ�y(t��ng)�У���ݔ?sh��)Ĕ?sh��)��(j��)����Ҫ�M(j��n)�и�ʽ�D(zhu��n)�Q�����ڹ��w��ݔ�r(sh��)�Ĵ��и�ʽ�������̎��r(sh��)�IJ��и�ʽ֮�g�D(zhu��n)�Q��������-��� ��һ�㱻�Q���������D(zhu��n)�Q���� �����Á팍(sh��)�F(xi��n)�@�N�D(zhu��n)�Q�ġ��������D(zhu��n)�Q���c��늂������g�Ľӿ�ͨ������ٴ��Д�(sh��)��(j��)��������һ�N���a������(sh��)�F(xi��n)��ͬ����@�ӿɏĔ�(sh��)��(j��)�֏�(f��)Ƕ��ĕr(sh��)犡�ҕ����֧�ֵ�ͨ�Ř�(bi��o)��(zh��n)��ԓ����������1.25Gb/s ��ǧ����̫�W(w��ng)����2.488Gb/s ��OC-48 / STM-16����9.953Gb/s ��OC-192 / STM-64�� ��10.3Gb/s ��10ǧ����̫�W(w��ng)���l����ݔ��
b.�������D(zhu��n)�Q�����Ɏ����ӿ�
��Sonet / SDH�������У����w�еĔ�(sh��)��(j��)��ݔ�������Î�����ʽ��ÿ������������Ϣ������ͬ�����`��O(ji��n)ҕ�����o(h��)�ГQ�ȣ�����Ч�d�ɔ�(sh��)��(j��)����ݔ�O(sh��)������ݔ����(sh��)��(j��)�м��뎬�ĸ�����Ϣ�������O(sh��)��t��횏Ď�����ȡ��Ч�d�ɔ�(sh��)��(j��)�����Î��ĸ�����Ϣ�M(j��n)��ϵ�y(t��ng)�������@Щ��������(hu��)�ڳɎ�������ɡ�
���ڳɎ�����Ҫ��(sh��)�F(xi��n)ijЩ��(f��)�s�Ĕ�(sh��)��߉������Q���˴������D(zhu��n)�Q���c�Ɏ����g���õĽӿڼ��g(sh��)�����Ø�(bi��o)��(zh��n)CMOS��ˇ����ĸ��ɶ�IC.Ŀǰ��CMOS��ˇ����֧��10Gb/s���Д�(sh��)��(j��)�����M�ܺܶ����J(r��n)��δ����CMOS��ˇ���Ԍ�(sh��)�F(xi��n)���(xi��ng)���ܣ�,��˴������D(zhu��n)�Q���c�Ɏ����g��Ҫ���нӿڡ�Ŀǰ�����е��x�����ɹ�W(w��ng)�j(lu��)��(li��n)Փ�� ��Optical Internetworking Forum�� �_�l(f��)��SFI-4,ԓ�ӿ�ʹ�Ãɂ�(g��)�ٶ��_(d��)622Mb/s��16λ���Д�(sh��)��(j��)����ÿ��(g��)����һ��(g��)��.SFI-4�cĿǰ�ܶ����d�ӿ�һ�ӣ�ʹ��Դͬ���r(sh��)犣����r(sh��)���̖(h��o)�c��(sh��)��(j��)��̖(h��o)��ͬ�ɂ�ݔ������ݔ��Դͬ���r(sh��)犿��@�����͕r(sh��)���̖(h��o)�c��(sh��)��(j��)��̖(h��o)�g��ƫ�ƣ�����������ȫ������ƥ��PCB��·�L(zh��ng)�������ƫ��Ч��(y��ng)��16��(g��)��(sh��)��(j��)��̖(h��o)�͕r(sh��)���̖(h��o)��ʹ��IEEE-1593.6��(bi��o)��(zh��n)LVDS���ԓ�ӿڃH���ڴ������D(zhu��n)�Q���c�Ɏ����g����ݔ��(sh��)��(j��)�����x�^�̣���˟o��߂��(f��)�s�������ƻ��`��z�y(c��)���ܡ�
��̫�W(w��ng)��Ҳ������ƽӿڡ���10ǧ����̫�W(w��ng)PHY���������a�ӌӣ�PCS���c�������|(zh��)�B�ӣ�PMA����֮�g��IEEE-802.3aeҎ(gu��)���ṩ��һ�N���Q��XSBI�Ľӿڡ��@�N��10ǧ��16λ�ӿڡ���ÿ��(g��)������16λ���Д�(sh��)��(j��)����Դͬ���r(sh��)犡���(sh��)��(j��)�͕r(sh��)犾�ʹ��IEEE-1593.6��(bi��o)��(zh��n)LVDS�����(sh��)��(j��)ͨ��ʹ��64b/66b���a��������r(sh��)��l�ʞ�644MHz.
ԓ10ǧ����̫�W(w��ng)Ҏ(gu��)��ʹ�ô��нӿ��B��MAC�����|(zh��)�L�����ƣ��Ӻ�PHY���������ӡ��@��(g��)���Q��XAUI�Ľӿڣ�Ҳ���Q�顰10ǧ���B�ӆ�Ԫ�ӿڡ�,�@��һ�Nʹ����ͨ���Ĵ��нӿڣ�ÿ��(g��)ͨ����ݔ2.5Gb/s��Ч�d�ɔ�(sh��)��(j��)��8b/10b���aʹÿ��(g��)ͨ���ı����ʸ��_(d��)3.125Gb/s.ԓ�ӿ�һ�������B��MAC�Ͱ���PHY���������Ī�(d��)��ģ�K������(j��)�������̵Ķ�Դ�f(xi��)�h�_�l(f��)��Xenpak��ģ�Kʹ��XAUI�ӿڡ�����߀���ᵽXAUIҲ����ϵ�y(t��ng)���塣
c.�Ɏ����c�W(w��ng)�j(lu��)̎����������Ԫ���g�Ľӿ�
�Ɏ����c�W(w��ng)�j(lu��)̎���g��ݔ?sh��)Ĕ?sh��)��(j��)�ɴ����ܶͬ�Ĕ�(sh��)��(j��)����Sonet/SDH���а����ĸ��Ӕ�(sh��)��(j��)������(sh��)��(j��)��Ч�d����ÿ��(g��)��(sh��)��(j��)����λ�ã�ԓ��Ϣ��Ҫ�ڳɎ����c�W(w��ng)�j(lu��)̎���������P(gu��n)�����g��ݔ��������������������������⣬�W(w��ng)�j(lu��)̎���������P(gu��n)����߀��(sh��)�F(xi��n)���N��(f��)�s���΄�(w��)���电(sh��)��(j��)�����QоƬ�ĕr(sh��)���ţ����픵(sh��)��(j��)����(n��i)���Դ_���]�зǷ���(sh��)��(j��)�M(j��n)��W(w��ng)�j(lu��)���Լ��y(c��)�������Ա��ض���(y��ng)�û��Ñ����Ѓ�(y��u)�ș�(qu��n)�������@Щ�΄�(w��)��(f��)�s�������Ҫ�ڳɎ����c�W(w��ng)�j(lu��)̎�����g��(sh��)ʩ�����Ʒ�����
�Ɏ������W(w��ng)�j(lu��)̎�����c���P(gu��n)�����gͨ��ʹ�õĽӿڰ���Utopia�ӿڡ�POS-PHY�ӿڡ�SPI�ӿں�Flexbus�ӿڡ�ÿ��(g��)�ӿڵĺ�Y�� ��l(f��)evel X��,�伉(j��)�e������(bi��o)�Q��(sh��)��(j��)���ʡ�Level 2��ָÿ��(g��)����Ĕ�(sh��)��(j��)���ʞ�622Mb/s,Level 3��2.488Gb/s,level 4��9.953Gb/s,Level 5��39.8Gb/s.���POS-PHY Level 4�Ę�(bi��o)�Q������9.953Gb/s.Utopia�ӿ��Ǟ�����̶��L(zh��ng)��ATM��Ԫ�Ĕ�(sh��)��(j��)�����O(sh��)Ӌ(j��)�ġ�Utopia��Ҏ(gu��)����ATMՓ���C����
POS-PHY�ӿ� ��Sonet������ϵİ��� ��PMC-Sierra��Saturn�_�l(f��)���ܶ������cUtopia�ӿ���ͬ����һ�(xi��ng)���M(j��n)����ֵ��ע�⣬��POS-PHY�ܝM�㲻ͬ�L(zh��ng)�Ȕ�(sh��)��(j��)������Ҫ����Utopiaֻ�m���ڹ̶���Ԫ�L(zh��ng)�ȡ��@����POS-PHY�ӿ��Ǟ�o��ATM�ӣ�������Sonet/SDH��ݔ����ֱ�ӂ�ݔ�L(zh��ng)��׃����IP���đ�(y��ng)�ö��O(sh��)Ӌ(j��)�ģ���˱��Q����Sonet�ϵĔ�(sh��)��(j��)����.
Flexbus�ӿ���AMCC�_�l(f��)����̎��Sonet��ݔ���ϵ�׃�L(zh��ng)��IP����AMCC��Flexbus Level 4�ѫ@��W(w��ng)�j(lu��)��(li��n)Փ���ɼ{������SPI Level 4 Phase 1��һ��s���顰SPI-4.1����,���ѽ�(j��ng)����I(y��)���(bi��o)��(zh��n)Ҏ(gu��)���l(f��)����ԓҎ(gu��)����ÿ��(g��)�������ṩ64λ�����c(di��n)���c(di��n)��(sh��)��(j��)ͨ������ʹ��HSTL class 1 I/O,Դͬ���r(sh��)��l�ʞ�200MHz,߀�ṩ�ķ�֮һ���ʽӿں�16λ���Д�(sh��)��(j��)ͨ����
POS-PHY Level 4Ҳ�ѽ�(j��ng)����W(w��ng)�j(lu��)��(li��n)Փ���ɼ{��������SPI Level 4 Phase 2 ��ͨ���s���顰SPI-4.2����.ԓ�ӿھ��в���IEEE-1593.6��(bi��o)��(zh��n)LVDS��16λ���Д�(sh��)��(j��)ͨ����Դͬ���p��(sh��)��(j��)���ʕr(sh��)��l����С��311MHz.SPI-4.2���S����(y��ng)�Ätʹ���l�ʸ��ߵĕr(sh��)犣���?y��n)�ԓ�ӿڳ��˂�ݔ�?sh��)��(j��)��Ч�d���⣬߀���Ͱ���(bi��o)����·����Ϣ����ˣ��O(sh��)Ӌ(j��)�߳�������SPI-4.2,ÿ��(g��)��̖(h��o)��(du��)�Ĕ�(sh��)��(j��)���ʸ��_(d��)840Mb/s,ÿ��(g��)�������Ӌ(j��)�������_(d��)13.4Gb/s.
�M��SPI-4.2�Ǟ�Sonet�ϔ�(sh��)��(j��)�����_�l(f��)�����ѱ�ͨ�ŘI(y��)��������(y��ng)�����ɼ{��������֧�ֶ���(sh��)��(j��)������ÿ��(g��)��(sh��)��(j��)���ж����������Ƶ��`��ӿڣ���������10G��̫�W(w��ng)����Ч�ӿڣ�߀�����ڴ惦(ch��)�^(q��)��W(w��ng)�j(lu��)��SAN��.Ŀǰ�Ј�(ch��ng)���и��N����SPI-4.2�ӿڵ��®a(ch��n)Ʒ��߀��һЩ�a(ch��n)Ʒ�����_�l(f��)֮�У�����Sonet / SDH�Ɏ����;W(w��ng)�j(lu��)̎������߀����TCP ж�d���棨TOE����10G��̫�W(w��ng)MAC.
d.�W(w��ng)�j(lu��)̎�����c���Q�ܘ�(g��u)�g�Ľӿ�
�W(w��ng)�j(lu��)̎�����c���P(gu��n)���������Q�ܘ�(g��u)�g�Ľӿ��ЃɷN
��ͣ�һ鲻��Ҫ�ڱ����ݔ��(sh��)��(j��)�Ľӿڣ���һ���Ҫ�ڱ����ݔ��(sh��)��(j��)�Ľӿڡ���(du��)�ڵ�һ�N�ӿڣ�λ��ͬһ�K�·��ľW(w��ng)�j(lu��)̎����оƬ�M�ͽ��Q�ܘ�(g��u)�g�Ľӿڿ���CSIXLevel1�ӿڌ�(sh��)�F(xi��n)��ԓ�ӿڲ���CSIXLev��
��ͣ�һ鲻��Ҫ�ڱ����ݔ��(sh��)��(j��)�Ľӿڣ���һ���Ҫ�ڱ����ݔ��(sh��)��(j��)�Ľӿڡ�
��(du��)�ڵ�һ�N�ӿڣ�λ��ͬһ�K�·��ľW(w��ng)�j(lu��)̎����оƬ�M�ͽ��Q�ܘ�(g��u)�g�Ľӿڿ���CSIX Level 1�ӿڌ�(sh��)�F(xi��n)��ԓ�ӿڲ���CSIX Level 1����ʽ�������齻�Q�ܘ�(g��u)�ṩ·��ָ��Ĉ�(b��o)�^���Լ������`��z�y(c��)���m���Ĉ�(b��o)β��߀������(sh��)��(j��)�d�ɱ���������CSIXҎ(gu��)���ľW(w��ng)�j(lu��)̎����Փ�����M(j��n)һ������ԓҎ(gu��)�������ӏ�һ��(g��)NPUоƬ�Mͨ�^���QоƬ�����킀(g��)NPUоƬ���~��ָ��@���ɞ�CSIX Level 2Ҏ(gu��)��������Ҫ���M(j��n)����ԓҎ(gu��)��߀���x��ÿ��(g��)������ʹ������128��(g��)HSTLһ�I/O��늚⻥�B����Դͬ���r(sh��)��l�ʸ��_(d��)250MHz.CSIX Level 1�f(xi��)�h�cCSIX Level 1늚�Ҏ(gu��)���o�P(gu��n)���oՓNPUоƬ�M�ͽ��Q�ܘ�(g��u)�g�Ľ�(j��ng)�ɱ����ͨ�Ų��úηN늚��(bi��o)��(zh��n)���Կ�ʹ��CSIX Level 1�f(xi��)�h��
��(du��)�ڵڶ��N�ӿڣ���NPUоƬ�M�c���Q�ܘ�(g��u)�g��Ҫ��ͨ�^����ͨ�ţ���Ȼ����ʹ��CSIX Level 1�f(xi��)�h�����@�N늚�ӿڲ������m����̖(h��o)�����^�B�������Ķ˿ڿ����_(d��)ϵ�y(t��ng)���壬��(j��ng)�^��(sh��)Ӣ�絽�_(d��)��һ��(g��)�B������Ȼ���M(j��n)�뽻�Q�������T��ԭ��ʹ��Խ��Խ����O(sh��)Ӌ(j��)���x�����Ƕ��ʽ�r(sh��)犵Ĵ��нӿځ팍(sh��)�F(xi��n)�@Щ�B�ӡ����ȣ����нӿڿ�����ȵp���·���c�����B���������_��(sh��)���Ķ��ɜpС���������(du��)����ϵ�y(t��ng)���·��Ŀ��ܓp�������������̖(h��o)��Ƕ��r(sh��)犺͔�(sh��)��(j��)�Ĵ��нӿڿ���ȫ����r(sh��)�ƫ�Ɔ��}���r(sh��)�ƫ����PCB�Д�(sh��)Ӣ���L(zh��ng)�IJ��������R����Ҫ���}��������������̖(h��o)�ı����O(sh��)Ӌ(j��)��߀����߂�ݔ���ʣ���?y��n)鲻���ڕr(sh��)�ƫ�ƣ�Ҳ�͛]�Ќ�(du��)δ�����ܵ����ơ�
���ɹ��������б����(bi��o)��(zh��n)�Ľӿ���XAUI,���Ǟ�10ǧ����̫�W(w��ng)�_�l(f��)�ġ�ԓҎ(gu��)���m����ͨ�������·���oՓ��ͨ��܉���L(zh��ng)���Ƿ�ƥ�䣬����XAUI���������ܽ��՟o�`�(sh��)��(j��)��ԓ�ӿ�ʹ�ò�����ģʽ߉�����߀���ý������ģʽ�����S�·���g�ą���늉���ͬ��
e.���ư�ӿ�
Ŀǰ�������ᵽ�Ľӿڶ����ڡ���(sh��)��(j��)ͨ����,����(sh��)��(j��)�Ĺ��w��ݔ���|(zh��)���_(d��)���Q�ܘ�(g��u)��Ȼ�ع��wͨ����������ͨ��ϵ�y(t��ng)���Џ�(f��)�s�ġ����ư塱,ؓ(f��)؟(z��)�y(t��ng)Ӌ(j��)��(sh��)��(j��)�ռ��������O(ji��n)ҕ��ϵ�y(t��ng)�������S�o(h��)�ȹ��ܣ������Ҫ��(qi��ng)���̎�������\(y��n)��ܛ���Ԍ�(sh��)�F(xi��n)�@Щ���ܡ��@Щ��(g��u)�����ư�̎�����Ľӿ������O(sh��)����ǘӣ��c��(sh��)��(j��)ͨ���Ľӿ����@��ͬ����(sh��)��(j��)ͨ���ӿ���Ҫ�����ڃɂ�(g��)�����g��ݔ��(sh��)��(j��)�����c(di��n)��(du��)�c(di��n)朽ӣ�,���ư�ӿڄt���c���в�ͬԪ����һ��(g��)�����(g��)̎�������B�ӣ� �����հl(f��)����DSP����(sh��)��(j��)�������Ŀ��ƶ˿ڵȡ���(sh��)�F(xi��n)�@Щ�`��Ļ��B��Ҫ��ȫ��ͬ��͵Ľӿڡ�
�@�ϵ�y(t��ng)�^ȥ���LJ��@���c(di��n)��(f��)�ӵ����Ŀ�����(g��u)���ġ���(sh��)�F(xi��n)PCI�����ܘ�(g��u)��32λ/ 33MHz��������õ�64λ/ 66MHz��(bi��o)��(zh��n)�ѽ�(j��ng)����ͨ��ϵ�y(t��ng)�С����64λ/ 133MHz PCI-X�����ڸ߶˷���(w��)�������ǣ����ڔ�(sh��)��(j��)��̎���Ď����ѽ�(j��ng)���ӣ����ư�Ď���ҲҪ��ߡ��ܶ��O(sh��)Ӌ(j��)�߰l(f��)�F(xi��n)�����������������ԝM�����(g��)������������ˣ����F(xi��n)һ����ͽӿڡ�
�@��½ӿڲ����c(di��n)���c(di��n)�B�ӣ���Դͬ���r(sh��)犜p�ٕr(sh��)�ƫ�ơ�����������ߔ�(sh��)��(j��)��ݔ�ʣ��p�ٽ��Q�����ġ��������Ą�(chu��ng)������ʹ�ý��Q�ܘ�(g��u)��ͨ����������(sh��)�F(xi��n)���Ƒ�(y��ng)��������Ķ��c(di��n)���B��
�ѫ@��Motorola��RapidIO�Q(m��o)��(li��n)�ϕ�(hu��)֧�ֵ�RapidIO��ʹ�ý��Q�ܘ�(g��u)��(sh��)�F(xi��n)�c(di��n)���c(di��n)朽ӵĽӿڡ�ԓ�ӿڵĂ�ݔ��Ҏ(gu��)����(sh��)��(j��)��η��b�ڰ��У�ÿ��(g��)�������Д�(sh��)��(j��)Դ��Ŀ��(bi��o)��Ϣ�����Q�ܘ�(g��u)����(sh��)��(j��)���������m��Ŀ�ĵء�RapidIO��ÿ��(g��)�������ṩ8��(g��)��16��(g��)λ������250MHz��1.0GHz�p��(sh��)��(j��)���ʡ����⣬����RapidIO��ʹ�þ���8b/10b���a��1ͨ����4ͨ����(sh��)��(j��)��Ƕ��r(sh��)��_(d��)3.125Gb/s,��߀����CML������Motorola�ѽ�(j��ng)�Ƴ��Nʹ�ò���RapidIO��ͨ��̎������
AMD��HyperTransport(li��n)���_�l(f��)��HyperTransportʹ��ͨ��������(sh��)�F(xi��n)�c(di��n)���c(di��n)朽ӡ���(sh��)��(j��)������ʽ��ݔ��ÿ��(g��)����������(sh��)��(j��)Դ��Ŀ��(bi��o)��Ϣ�����Ք�(sh��)��(j��)��ͨ���������Ք�(sh��)��(j��)����(b��o)�^�_���nj���(sh��)��(j��)������е���һ��(g��)������߀��ֱ��̎�픵(sh��)��(j��)��Ŀǰ��HyperTransportҎ(gu��)����Ҫ���Ȟ�2��16λ�IJ��Д�(sh��)��(j��)��δ��Ҏ(gu��)����֧�ָ������ʡ�PMC-Sierra��Broadcom�ѽ�(j��ng)��HyperTransportͨ�Ůa(ch��n)Ʒ�Ƴ�����MIPS��̎������
PCI-SIG�ѽ�(j��ng)�Ƴ�������PCI-X.����ʹ���c���PCI-X��ͬ��64λ������������֧���p��(sh��)��(j��)���ʺ��ı���(sh��)��(j��)���ʡ�PCI-X 533���������İ汾�����Ӌ(j��)�����_(d��)34.1Gb/s.
��Q�ӿڛ_ͻ
�O(sh��)Ӌ(j��)���̎�����挦(du��)�@Щ����ʏ�s�Ľӿژ�(bi��o)��(zh��n)����(sh��)�H�ϣ���(du��)�ڽo�����O(sh��)Ӌ(j��)��r���O(sh��)Ӌ(j��)���x��ӿڵ���ز���������һ�����(j��)ϵ�y(t��ng)����ijɱ������ܣ��x����m�Ę�(bi��o)��(zh��n)�a(ch��n)Ʒ���O(sh��)Ӌ(j��)�߱���x������m�����������@���܌�(d��o)�½ӿژ�(bi��o)��(zh��n)�_ͻ����?y��n)���õĘ?bi��o)��(zh��n)�������ڽӿژ�(bi��o)��(zh��n)�����ݣ���(hu��)�������Ԇ��}�����@�N��r�£��O(sh��)Ӌ(j��)�߿�����x�������x���c�ӿڼ��ݵĘ�(bi��o)��(zh��n)�����������ܕ�(hu��)��ɲ��ܝM�㹦����Ҫ��ϵ�y(t��ng)�ijɱ�Ҫ����ʹ�Ø���������_�����ݵĽӿڡ��F(xi��n)���ѽ�(j��ng)�Ƴ��ܶ���и����ܽӿ�IP����������I/O��FPGA,�ɝM��10Gb/s���ϔ�(sh��)��(j��)ͨ����ͨ��ϵ�y(t��ng)��Ҫ��
Actel�����_�l(f��)���N�ɾ���߉�������Y(ji��)�ϸ�(j��)�ӿڼ��g(sh��)�������Ƴ���Axceleratorϵ�и���FPGA�ܘ�(g��u)����a(ch��n)Ʒ���������ʸ��_(d��)3.125Gb/s�ļ��ɴ������D(zhu��n)�Q��ͨ����Ӳ�B���������a�ӌӣ��������Ԅ�(d��ng)̎��XAUI�ʹ���RapidIO�����8b/10b���a��ͨ�����С��@Щ����߀���Ќ�(sh��)�F(xi��n)LVDS����ĸ���ͨ��I/O,�ɽ���ʹ��SPI-4.2��HyperTransport�Ͳ���RapidIO�Ƚӿژ�(bi��o)��(zh��n)���@Щ����߀�����ɸ��N֪�R(sh��)�a(ch��n)��(qu��n)��(n��i)�ˣ��Ա㑪(y��ng)����Ҫ����̵Ę�Ӯa(ch��n)Ʒ��]]>

Stratix III FPGAоƬ�D��

StratixIV FPGAоƬ�D��
�ڱ��ĵ�һ���ֵ�ӑՓ�У��҂�֪������Ŀǰ�Ļ���FPGA�ĈD��̎���O(sh��)Ӌ(j��)���̣���C++�ȸ�(j��)�Z�Ծ������㷨����(sh��)ģ�ͱ�횲����ք�(d��ng)��ʽ���a��RTL�����ք�(d��ng)����RTL�ķ��������ĕr(sh��)���������׳��e(cu��)����(du��)��˲����ӕr(sh��)���}�dz����С�����҂���횿��]�����܉��ANSI C++��ģ�㷨Ѹ���D(zhu��n)�Q���\(y��n)����FPGAӲ���е�RTL��(sh��)�F(xi��n)�������ڽ����ĵڶ�����ӑՓ�У��҂��͌�ӑՓ�������Catapult��ASIC���ܺ�Altera���َ�(k��)�Ԅ�(d��ng)�����(sh��)�F(xi��n)�@һ�O(sh��)Ӌ(j��)�^�̡�
�������(sh��)�F(xi��n)�@һ�dz��ĕr(sh��)���^�̣�Catapult C��(j��)�C���O(sh��)Ӌ(j��)�^�����Ȍ�(du��)�㷨�M(j��n)��������Ȼ���x��Ŀ��(bi��o)���g(sh��)���㷨�����Ǽ����ANSI C++Դ���a��ֻ��(du��)�����M(j��n)���f�������кͽӿڅf(xi��)�h��Ӳ��Ҫ���ͨ�^�s����Catapult�Ќ�(sh��)�F(xi��n)���Ķ�Ҳָ��(d��o)�˾C���^�̡�
���磬������㷨��һ��(g��)�������ޛ_��푑�(y��ng)(FIR)�V������ʹ�����M(f��i)��Mentor Graphics Algorithmic C��(sh��)��(j��)���(��朽�)�����x�ӿں̓�(n��i)��λ���ȡ�
C++�㷨���]���f����Ҫ���ٳ˷����Լ�ʲô��͵ij˷����팍(sh��)�F(xi��n)Ӳ������ˣ�ϵ�y(t��ng)Ҏ(gu��)���ˆT�����ڌ�(sh��)ʩ��(x��)��(ji��)�ϻ��M(f��i)̫�ྫ�����܉���Ч�Ľ����㷨��
��һ���Ǵ_��Ŀ��(bi��o)���g(sh��)���P(gu��n)�IҎ(gu��)������Catapult�У�Ŀ��(bi��o)���g(sh��)������ASIC����FPGA���cԴ���a�����o�P(gu��n)��Catapult C�C��ʹ�Ì��ü��g(sh��)��(k��)��������(sh��)����������\(y��n)���(k��)������ӷ����ͳ˷����ȡ��@һ���������^���ռ����������YԴԔ��(x��)����e�͕r(sh��)����Ϣ��ʹCatapult�܉������g(sh��)�A(y��)֪Ӌ(j��)��������(hu��)���M(f��i)HLS̽���^����RTL�C�ϕr(sh��)�g����Y(ji��)���ǿ��ٵ�ǰ����e/���ܹ��㣬�õ����ü��g(sh��)RTLݔ����
ָ����Ŀ��(bi��o)���g(sh��)�Լ��r(sh��)��l�ʺ��O(sh��)Ӌ(j��)�ˆT����ʹ���Ԅ�(d��ng)��(j��)�C�ϼ��g(sh��)���ɵ��M(j��n)���O(sh��)Ӌ(j��)�������Ԅ�(d��ng)�^�̱��ք�(d��ng)RTL���a��ö࣬�O(sh��)Ӌ(j��)�ˆT�܉��P(gu��n)ע������x�(xi��ng)���C�Ͽ��]��e�����ܣ�����(sh��)�F(xi��n)��Ӳ����ȫ�M���O(sh��)Ӌ(j��)Ŀ��(bi��o)Ҫ��(j��)�C�Ϲ��ߌ�(du��)Ŀ��(bi��o)���g(sh��)�dz����������(j��)�r(sh��)��l��Ҫ����x����m���\(y��n)�㣬����Ҫ�ĵط�����ϵ�y(t��ng)��(j��)��ˮ�����_������(hu��)�`���r(sh��)��l�ʼs�����O(sh��)Ӌ(j��)�ˆT����ʹ���_�h(hu��n)�ͭh(hu��n)��ˮ���ȸ�(j��)�C�ϼs�����о�����̴�(li��n)��ȫ��(li��n)��(sh��)�F(xi��n)�Ķ�N�wϵ�Y(ji��)��(g��u)(��(du��)�ȈD1�͈D2�еľ��w��(sh��)�F(xi��n))��

�D1����(li��n)FIR��(sh��)�F(xi��n)��

�D2����(li��n)FIR��(sh��)�F(xi��n)��
�ڽ����ĵ�������ӑՓ�У��҂���ӑՓ����x���{(di��o)������Ҫ���\(y��n)���ԝM��r(sh��)��l�ʼs�����Լ���β��ø�(j��)�C���YԴ�s����pС����߾��ӕr(sh��)����Ո(q��ng)���⡣
]]>| ����(n��i)�ݺ��_��,����܌�(d��o)����治�����Ĵ��a |
|---|
| �f���������@ʾ���Ǵ��a��(n��i)�ݡ��������șz���^���a�]���}������֮�����\(y��n)��. |
�������M(f��i)����ܷ�֧��FPGA�a(ch��n)�I(y��)
�������M(f��i)����Ј�(ch��ng)�ܵ������L(f��ng)����Ӱ��Ȟ鄡�ң���˲�ͬ��FPGA�S�̌�(du��)���M(f��i)����Ј�(ch��ng)��ǰ�����S�ࠎ(zh��ng)Փ��Altera��ϯ��(zh��)�й٣�CEO��������(hu��)��ϯJohn Daane�J(r��n)�飬���خa(ch��n)��ĭ�����ķ��s���o���M(f��i)�~�������ȥُ(g��u)�I��������M(f��i)��Ӯa(ch��n)Ʒ���s��40%����Ӯa(ch��n)Ʒ�������M(f��i)�ԣ��ټ��ϳ��^30%�c��X���P(gu��n)�Įa(ch��n)Ʒ�����Ԍ�(sh��)�H�Ͻӽ�75%�Ј�(ch��ng)�Ķ������M(f��i)�I(l��ng)��Ŀǰ��������ԓ�ИI(y��)�ܵ��ě_����ͬ�r(sh��)����(gu��)����һ��(g��)���M(f��i)���(gu��)�ĕr(sh��)��Ҳ�ص��h(yu��n)ȥ��������Ѱ댧(d��o)�w�a(ch��n)�I(y��)���ֳɲ�ͬ�ļ�(x��)���Ј�(ch��ng)���Ϳ��Կ����o��ͨӍ��܊�õȱ������I(l��ng)���̎��Ҫ�ã����FPGA�S�̑�(y��ng)ԓ�����c(di��n)�����@Щ�����L(zh��ng)���Ј�(ch��ng)��
�й٣�CEO��������(hu��)��ϯJohn Daane")
�D1��Altera��ϯ��(zh��)�й٣�CEO��������(hu��)��ϯJohn Daane
����FPGA�S��SiliconBlue��ϯ��(zh��)�й�Kapil Shankar�s�J(r��n)�飬���M(f��i)�Ј�(ch��ng)��˥�˲�����(hu��)��һ��(g��)�L(zh��ng)�ڵĬF(xi��n)����K��(hu��)�(q��)��(d��ng)�������FPGA�a(ch��n)Ʒ�Įa(ch��n)�������e���f���ϾW(w��ng)��Ŀǰʹ����ͨ�Pӛ����̎���������ȱ�������Ƅ�(d��ng)��������һ���棬Ƕ��ʽ�Ƅ�(d��ng)̎�����ַ���ȱ�����Ĺ��ܣ���D�κ�ҕ�l�@ʾ��ͶӰ�ȡ����@Щ�I(l��ng)��ʹ��FPGA�t�Ǻ������x�ɞ�a(ch��n)Ʒ���Ӽ��ɶȺ��Ƅ�(d��ng)�Ե�ͬ�r(sh��)���C�S���Ĺ��ܣ����Â��y(t��ng)ASIC������С�������ƻ��a(ch��n)Ʒ�Ќ�(sh��)�F(xi��n)�^�͵ijɱ���
�й�Kapil Shankar")
�D2��SiliconBlue��ϯ��(zh��)�й٣�CEO��Kapil Shankar
����Actel�tͨ�^�����Flash FPGA�a(ch��n)Ʒ�M(j��n)�����M(f��i)�I(l��ng)��Actel������Richard Kapusta�f�����IJ��������Ϳ�·�����?y��n)�?du��)���ĵĜy(c��)�����]��һ��(g��)��(zh��n)�_�����Ƶķ������c����SRAM�ļ��g(sh��)��ͬ������Flash��FPGA�a(ch��n)Ʒ�ĽY(ji��)��(g��u)�ώ������������ă�(y��u)��(sh��)��ֻ�Ђ��y(t��ng)SRAM��ǧ��֮һ��ͬ�r(sh��)��F(xi��n)lash�ܘ�(g��u)����С�ߴ硢��оƬ�ă�(y��u)��(sh��)��߀������������ȫ����(w��n)�������⣬�����̖(h��o)FPGA���Ј�(ch��ng)���³ɆT�����������������䲢����ȫᘌ�(du��)�ͳɱ�����đ�(y��ng)�ã�����Ҫ����ϵ�y(t��ng)��(sh��)�F(xi��n)

�D3��Actel������Richard Kapusta
�����Ƴ̹�ˇ�Ƿ�����˰댧(d��o)�w��һ��
����John Daaneָ����ASIC�������f���Ƴ̼��g(sh��)��ԇ�D�S���ԃr(ji��)�ȣ����ɾ��������s�ܱ���ǰ�M(j��n)�IJ���������Ҫ�I(l��ng)��3~4�����댧(d��o)�w�ijɱ��S���A�ߴ�ʎμ�(j��)��(sh��)���ӣ��ɾ���߉�����t��������(sh��)�F(xi��n)��С�ľ��A�ߴ磻��������c����DDR3��Ŀǰ�������惦(ch��)���g(sh��)���¹��܌�(sh��)�F(xi��n)�ӿڣ�130nm��ASIC�����ܝM�������������
����ASIC�S�̄t��(du��)�Ƴ̹�ˇ�������ֱ����B(t��i)�ȡ���(chu��ng)����ӣ�Global Unichip���Ј�(ch��ng)�����O(ji��n)�S���ڲ�ʿ�f��F(xi��n)PGA�mȻ�������M(j��n)���Ƴ̼��g(sh��)��Ч�Ƅ�(d��ng)��оƬ�ĸ��(xi��ng)ָ��(bi��o)�����μ��Ƴ̵����M(j��n)�����ԝM�㑪(y��ng)�Ì�(du��)���ܲ������ӵ��������⣬���Ď��ѽ�(j��ng)�ɞ����Б�(y��ng)�õ�����֮�أ����@Щ����FPGA�����(xi��ng)�����Ј�(ch��ng)�Ƕȿ���F(xi��n)PGAֻ��(y��ng)����С�����Ј�(ch��ng)�����Ј�(ch��ng)����K���������w��؛�������ò����J(r��n)ASIC���S��ˣ�������Fabless�����Sģʽ������Ҫ��ij��(g��)�O(sh��)���(y��ng)�ÆΪ�(d��)Ͷ�Yһ�Ҿ��A�S��Ҳ�ͱ������σ|��Ԫ�L(f��ng)�U(xi��n)�O�ߵ�Ͷ�Y�������Ć��}Ҳ����ӭ�ж��⡣
����ӣ�Global Unichip���Ј�(ch��ng)�����O(ji��n)�S���ڲ�ʿ")
�D4����(chu��ng)����ӣ�Global Unichip���Ј�(ch��ng)�����O(ji��n)�S���ڲ�ʿ
��(j��)������Vincent Ratford")
�D5��Xilinxȫ���Ј�(ch��ng)��(j��)������Vincent Ratford
������(du��)���Ƴ̹�ˇ֮��(zh��ng)����FPGA�S��֮�gҲ���ڲ�ͬ�Ŀ�����Xilinxȫ���Ј�(ch��ng)��(j��)������Vincent Ratfordָ�����͑������H�H��оƬ��������������(g��)��Q�������Լ�������@Щ������(sh��)�F(xi��n)����(f��)�s�đ�(y��ng)�á�äĿ�؛_���Ƴ̼��g(sh��)�ϵ��¹�(ji��)�c(di��n)�����H�H��(chu��ng)��һ��(g��)�Ϊ�(d��)��оƬ�����g(sh��)�����O(sh��)���h(yu��n)�h(yu��n)���]������IP��ܛ����֧��Ҳ�������Ј�(ch��ng)����Ҫ�ġ���ˣ��S�̱���܉�ᘌ�(du��)ij��(g��)�ض��I(l��ng)���Ƴ��m�ϵĮa(ch��n)Ʒ�������]�����@Щ��(y��ng)�È�(ch��ng)���µĹ��ġ�����Ҫ��һ�c(di��n)�ǣ��͑���Ҫһ��(g��)�c����ASIC�O(sh��)Ӌ(j��)����ݵ��O(sh��)Ӌ(j��)�������@Ҳ��Xilinx����ġ�Ŀ��(bi��o)�O(sh��)Ӌ(j��)ƽ�_(t��i)�������һ��(g��)��ҪԪ�ء�
Ʒ���ĸ�(j��)���O(ji��n)Dave Greenfield")
�D6��Altera HardCopy�a(ch��n)Ʒ���ĸ�(j��)���O(ji��n)Dave Greenfield
����Altera HardCopy�a(ch��n)Ʒ���ĸ�(j��)���O(ji��n)Dave Greenfield��ʾ����(y��ng)��FPGA������(d��o)�a(ch��n)Ʒ��ǰ���_�l(f��)����Ҫ���ǣ�������Įa(ch��n)Ʒ������ṩ�o���ܛ���_�l(f��)�F(tu��n)�(du��)�����ڿ͑����Ŀ͑��@�ü��r(sh��)�ķ���ʮ�ֱ�Ҫ��ܛ�����T������^��صõ��a(ch��n)Ʒ���t�Ɍ�(du��)���a�M(j��n)�и���ă�(y��u)��������ǰ����FPGA�_�l(f��)��ͨ�^ASIC��(sh��)�F(xi��n)���������a(ch��n)��ģʽ��ϵ�y(t��ng)�ɱ���Ч���ͣ�
]]>�D16. 16λSPIͨ�ų����D
�D16�У��ⲿWhileѭ�h(hu��n)�_�������д��a�����B�m(x��)��(zh��)�У������벼��ݔ��ؼ��tͨ�^�l���Y(ji��)��(g��u)����(d��ng)����(sh��)��(j��)���f�� ���Y(ji��)��(g��u)�еĵ�һ��܌�Ƭ�x���ƾ���chip select line)�O(sh��)�Þ���ƽ��֮�������g��܌��딵(sh��)��(j��)λ�����r(sh��)犾��ГQ16�Ρ� ��K����������?q��)�Ƭ�x���ƾ���chip select line)�O(sh��)�û�TRUE��B(t��i)��������(sh��)��(j��)�����Þ�Ĭ�J(r��n)��FALSE��B(t��i)�� �@һ��(ji��n)�η���ֻ�ǽ�������DAQ�M(j��n)�Д�(sh��)��ͨ�ŕr(sh��)��һ�(xi��ng)��(n��i)�ݡ� �Ñ����둪(y��ng)�Ô�(sh��)�����֣������ACK�����ã���REQ����ͣ������(zh��n)��2·ͨ��������һ·ͨ���������\(y��n)���ĕr(sh��)���̖(h��o)�͔�(sh��)��(j��)����
��(sh��)�־���(hu��)�r(sh��)������(d��ng)����ʹ�ÙC(j��)늽��|�r(sh��)������ˣ�Ȼ���Ñ���ͨ�^NI LabVIEW FPGA���x��ͬ��ʽ���ڔ�(sh��)��ݔ�뾀������ȥ����(d��ng)�V������ ��������B(t��i)���e(cu��)�`�Ą�(d��ng)�r(sh��)����(sh��)��ȥ����(d��ng)�V�����_����(sh��)ֵ��׃���܉�һ����̵ĕr(sh��)�g�����Ҏ(gu��)������(d��ng)���l(f��)���e(cu��)�`�xȡ�� �D17չ�F(xi��n)�����ͨ�^����DAQ��(sh��)�F(xi��n)���(xi��ng)���ܵă�(n��i)�ݡ�
�D17. ����DAQӲ���ϵĔ�(sh��)�֞V���������D
��(sh��)��(j��)��ݔ��ʽ
���NI-DAQmx�(q��)��(d��ng)����Ă��y(t��ng)���DAQ������DAQ֮�g��������ڣ���(sh��)��(j��)��ݔ?sh��)Ĉ?zh��)�з�ʽ�� NI-DAQmx�(q��)��(d��ng)����?q��)��Г?d��n)���O(sh��)�������C(j��)�ĸ��(xi��ng)��ݔ�΄�(w��)�����(xi��ng)������NI LabVIWE FPGA��(hu��)��(du��)����FPGA�����а��dӲ���M(j��n)�о��̡� �Ñ���ͨ�^��N;�����_�O(sh��)���ϵİ��d��(sh��)��(j��)����ʹ�ò�ͬ��ʽ���磺DMAͨ�����Д�Ո(q��ng)��ݔ��(sh��)��(j��)��
NI LabVIEW FPGA�е�FIFO���_�^(q��)��LabVIEW�(xi��ng)Ŀ�g�[���н������ã����ܽ������d��(n��i)���Ӳ��߉�@���\(y��n)�С� �D18�@ʾ����ν�(j��ng)���(xi��ng)Ŀ�g�[�����ڰ��d�K�惦(ch��)������������(sh��)��FIFO���_�^(q��)��
�D18. NI LabVIEW FPGA�е�FIFO����
FIFOһ��(j��ng)��(chu��ng)������������NI LabVIEW FPGA�����D�϶���(g��)ѭ�h(hu��n)֮�g�Ĕ�(sh��)��(j��)���f�� �D19�еķ����@ʾ����(sh��)��(j��)�ȱ��������(c��)ѭ�h(hu��n)�е�FIFO�����S�����҂�(c��)ѭ�h(hu��n)�е�FIFO���x����
�D19. ͨ�^FIFO�Ͷ�ѭ�h(hu��n)��(sh��)�F(xi��n)��NI LabVIEW FPGA�����D
ͬ��ͨ�^LabVIEW FPGA FIFO�@�Ñ�(y��ng)�õ�ֱ�Ӵ惦(ch��)���L��(DMA)ͨ�������(xi��ng)Ŀ�g�[���н�������Ƶ����á�
�D20. NI LabVIEW FPGA�е�DMA FIFO����
�D21. ͨ�^DMA FIFO��λ�M�b��(sh��)�F(xi��n)��NI LabVIEW FPGA�����D
���е�DMA FIFO��(sh��)��(j��)��ݔ���Ⱦ���32λ����ˣ���(d��ng)����fԴ��16λģ�Mݔ��ͨ���Ĕ�(sh��)��(j��)�r(sh��)�������܉�ϲ�2·ͨ����2��(g��)�ӱ��ϵĔ�(sh��)��(j��)���M(j��n)�Ђ�ݔ���Ķ���ߎ���ʹ���ʡ� �@���LjD21��չ�F(xi��n)��λ�M�b����(d��ng)��(sh��)��(j��)��ֱ�ӂ��f������Ӌ(j��)��C(j��)�ă�(n��i)����ͨ�^��Windows�h(hu��n)�����\(y��n)�е�NI LabVIEW���ӿں���(sh��)�����xȡ���D22����
�D22. ͨ�^DMA FIFO�xȡ��λ���b��(sh��)�F(xi��n)�����ӿڴ��a
��D22��ʾ�����ӿڳ����D����FPGA�K��VI��Ȼ��ʹ��Whileѭ�h(hu��n)�B�m(x��)�xȡDMA FIFO�� 32λ�Ĕ�(sh��)��(j��)���ֽ��2·16λͨ�����ڲ��ΈD���Ͻ��ܲɘӺ��L�ơ� ���ӿ�VI߀�܌�(du��)FPGA VIǰ����ϵĸ���@ʾ�ؼ���ݔ��ؼ��M(j��n)���x�����������@�N��r�£���ֹͣ���o��ݔ��ؼ�Ҳ�����롣
�Y(ji��)Փ
�M��DAQ-STC2�ȹ̶�ASIC�܉�M�㔵(sh��)��(j��)�ɼ��Ĵ����(sh��)����Ȼ����Ψ�н�������DAQ�л��ڿ���������FPGA��I/O���r(sh��)�Ϳ��ƣ����܌�(sh��)�F(xi��n)�߶��`���Ժ���ȫ���ơ� ����NI LabVIEW FPGA���|�l(f��)��ͬ���΄�(w��)�@���˺�(ji��n)������?y��n)�ͨ�^�L�ƈD�λ������D���ɳ�֝M���Ñ���������(d��)����ģ�M�͔�(sh��)��I/O��������DAQ������FPGA�ṩ�Č�(sh��)�H���С� Rϵ������DAQ�O(sh��)���ѽ�(j��ng)ᘌ�(du��)�����ʲɘӡ��Զ��xӋ(j��)��(sh��)���������l�ʸ��_(d��)40 MHz�İ��d�Q�ߣ����ܔ�(sh��)��(j��)�ɼ��M(j��n)���˸��(xi��ng)���ܵ�����
]]>- ������
- ��߉����
- ����
- �����(j��)����
FPGA �Ļ����͑��V���Ǹ��̵����Еr(sh��)�g�����S���Ĺ��ܡ�֧�ָ��N����l(f��)չ�Ę�(bi��o)��(zh��n)�����͵��L(f��ng)�U(xi��n)���F(xi��n)��(ch��ng)������(j��)���Լ����͵�ϵ�y(t��ng)�ɱ��ȡ��҂��� FPGA �a(ch��n)Ʒ�ɝM����������M(j��n)���ܡ����������ĺͳɱ���Ҫ��
Virtex-5 ϵ�нY(ji��)����65 �{��ˇ���g(sh��)�Ĺ��Ѓ�(y��u)��(sh��)�̈́�(chu��ng)���O(sh��)Ӌ(j��)��ԓ��(chu��ng)���O(sh��)Ӌ(j��)�������҂���(du��)�a(ch��n)Ʒ��(y��ng)�õĸ���������⡣�����У��Ҍ���(du��)Virtex-5 �����M(j��n)�и������������A(ch��)���g(sh��)��ͬ�r(sh��)��(ji��n)�̻�������I(l��ng)�ȵ�FPGA �ܘ�(g��u)�O(sh��)Ӌ(j��)����Ĺ��¡�
��ˇ���g(sh��)�ͼܘ�(g��u)��(chu��ng)��
Virtex-5 FPGA ����65 �{�����ŘO�����Ӽ��g(sh��)�� ʹ�����M(j��n)�Ĺ�M��ģ�K(ASMBLTM) �ܘ�(g��u)���Ҍ�(sh��)�F(xi��n)�˸���(j��)�e��ϵ�y(t��ng)���ɡ��@��(g��)ȫ�µĮa(ch��n)Ʒϵ���ṩ��һ��(g��)��(j��)ƽ�_(t��i)�����ԝM���Ñ�(du��)�ڽ�����и������ܡ������ܶȡ������ĺ��ͳɱ��Ŀɾ���ϵ�y(t��ng)�������L(zh��ng)�����M������һ��(g��)���߃ɂ�(g��)����Ҳ�S���^���ף���������(zh��n)�����҂�Ҫͬ�r(sh��)�M�������@Щ�����҂�ͨ�^�����M(j��n)��IC ��ˇ����(chu��ng)�µļܘ�(g��u)�Լ��·�O(sh��)Ӌ(j��)��Y(ji��)�ϣ��ɹ��ؑ�(y��ng)��(du��)���@Щ����(zh��n)�������� Virtex-4 ϵ��������ij���� ASMBL оƬ��D�ܘ�(g��u)�������ṩ��Ҫ�������YԴ��߉���惦(ch��)�������g(sh��)��I/O��IP�����(y��u)�M�ϣ��Ķ��������Ă�(g��)��ƽ�_(t��i)��(chu��ng)������їl����
- ᘌ�(du��)������߉�M(j��n)�Ѓ�(y��u)���� LX ƽ�_(t��i)
- ᘌ�(du��)���е��Ĵ��� I/O �ĸ�����߉�M(j��n)�Ѓ�(y��u)���� LXT ƽ�_(t��i)
- ᘌ�(du��)���е��Ĵ��� I/O �ĸ��������g(sh��)�ʹ惦(ch��)�ܼ��� DSP �M(j��n)�Ѓ�(y��u)����SXT ƽ�_(t��i)
- ᘌ�(du��)Ƕ��ʽ̎���ͳ����ٴ��� I/O �M(j��n)�Ѓ�(y��u)���� FXT ƽ�_(t��i)
����(du��)��Virtex-4 ϵ�У�Virtex-5 ϵ����������ߵ���̖(h��o)��ƽ���ٶ������30%�����������65%����(d��ng)�B(t��i)���Ľ�����35%��оƬ��e�sС��45%���Y(ji��)����(sh��)�F(xi��n)���_(d��)��ÿ�(xi��ng)���ܵ���ͳɱ���
�����ܺ��ܶ�
ExpressFabricTM ���g(sh��)��(sh��)�F(xi��n)��߉�;ֲ����B�������������ұ� (LUT)������(g��)��(d��)����ݔ���һ��(g��)�µČ�(du��)�ǻ��B�Y(ji��)��(g��u)�Y(ji��)����һ����D1 ��ʾ������(du��)�� Virtex-4 �ܘ�(g��u)���ԣ�ExpressFabric ���g(sh��)���ø��ٵ� LUT�Ӵ��Լ����ٵĴ����B�ӣ�����������(g��u)������(sh��)�F(xi��n)�˽M��߉���@�N�����s���˔�(sh��)��(j��)ͨ·���t���Ķ�������O(sh��)Ӌ(j��)���ܡ�

�D1 - Virtex-5 ExpressFabric ���g(sh��)
���M(j��n)��6-LUT ߉�Y(ji��)��(g��u)
�����ԁ�����ݔ�� LUT һֱ�ǘI(y��)���(bi��o)��(zh��n)�����ǣ���65 �{��ˇ�l���£����^�������·���e�ǻ��B�·����LUT �ij�Ҏ(gu��)�Y(ji��)��(g��u)���sС��һ��(g��)�����ı�����λ����ݔ��LUT (6-LUT) �H�H�� CLB ��e�����15% - ����ƽ�����ԣ�ÿ��(g��) LUT �Ͽɼ��ɵ�߉��(sh��)���s������40%�����ߵ�߉�ܶ�ͨ�����Խ��ͼ�(j��)(li��n) LUT �Ĕ�(sh��)Ŀ�����Ҹ��M(j��n)�P(gu��n)�I·�����t���ܣ���D2 ��ʾ��

�D2 - �����ܺ���e֮�g�_(d��)�����ƽ��
�҂��x����һ�͑��O(sh��)Ӌ(j��)������Ȼ��ʹ�� ISETM 8.1i ܛ����(sh��)�F(xi��n)ԓ��������(du��)��ÿ��(g��)�O(sh��)Ӌ(j��)���҂����^��Virtex-4 �� Virtex-5������(sh��)�F(xi��n)�����õ� LUT ��(sh��)Ŀ����������Ϣ����Ɲ�������������P(gu��n)(li��n)���D3 �е�ɢ�c(di��n)�D�@ʾ��X�S�ϵ����������ٷֱȺ�Y�S�ϸ���(j��) LUT ��(sh��)Ŀ�Ľ���Ӌ(j��)��ó�����e�sС�������@�N�µ�6-LUTExpressFabric ���g(sh��)�������������YԴ��(ji��)�s���涼���F(xi��n)��ɫ��
��ͬ�ڸ�(j��ng)��(zh��ng) FPGA ���ǣ�Virtex-5FPGA �ṩ�������� 6-LUT������Ԍ�������߉���߷ֲ�ʽ�惦(ch��)�����@�r(sh��) LUT��һ��(g��)64 λ�ķֲ�ʽ RAM �������p�˿ڻ����Ķ˿ڣ�����һ��(g��)32 λ�ɾ�����λ�Ĵ�����ÿ��(g��) LUT ���Ѓɂ�(g��)ݔ�����Ķ���(sh��)�F(xi��n)���傀(g��)׃���ăɂ�(g��)߉����(sh��)���惦(ch��)32 x 2 RAM ���أ���������16 x 2-bit ����λ�Ĵ����M(j��n)�й�����

�D3 - Virtex-5 FPGA �� Virtex-4 FPGA �O(sh��)Ӌ(j��)�����u(p��ng)�y(c��)����(zh��n)
�µČ�(du��)�nj�(du��)�Q���B
һ�N�µČ�(du��)�nj�(du��)�Q���Bģʽͨ�^�ڸ��ٵIJ��������Ы@�ø���Ŀ��g��������ܡ��P(gu��n)��Virtex-5 ��Virtex-4 FPGA ���Bģʽ(ÿ��(g��)�����δ���һ��(g��) CLB)�ı��^��Ո(q��ng)��Ҋ�D1��ͨ�^ɫ��(bi��o)���Կ�����ʹ��Virtex-5 FPGA ʹԓģʽ���ӌ�(du��)�Q��ͬ�r(sh��)���ø��ٵ����ӵ��_(d��)�˸���� CLB���{�貼�ֲ���ܛ�����ߣ��@�N��(du��)�Q�Կ���ȡ�ø��õĽY(ji��)����
�@Щ���Ԍ�(du��)�� Virtex-5 FPGA ���Ñ���f����ȫ���ģ������܉� ISE ܛ���Ԅ�(d��ng)��(zh��)�У��Ķ��������Ӻ�(ji��n)�εĿɲ����Ժ��õĿ��w���ܡ�
����ĵ����M(j��n) FPGA ��Q����
Virtex-5 ����ϵ�в����I(l��ng)�ȵ�65 �{�ס����ŘO�����ӡ�11 ���~������ CMOS ��ˇ���g(sh��)�������ŘO�����ӡ���ָ���ò�ͬ�ľ��w�ܖŘO�����Ӻ�ȵĔ�(sh��)Ŀ��I/O ���w�ܱ�횿��Գ��� 3.3V ��늉������ʹ������(du��)�^��������ӣ�����߉���������Ĺ�����ʹ�õij����پ��w�܄tһ����ó��������ӡ����ҵ��ǣ����������Ӻͳ����ֵ늉����ɱ���؎����^�ߵ�й©�����Ȼ����F(xi��n)PGA ���кܶྦྷ�w�ܲ���Ҫ�ܸߵ��ٶȣ��e����Щ���ô惦(ch��)��Ԫ������Virtex-4ϵ���_ʼ��Xilinx ���Ȳ����˵����N���g�ŘO�����Ӻ�ȣ����Tᘌ�(du��)�@һ��w�ܡ��@�N���ŘO�����ӷ������S�҂���(du��)�����·�����ܺ����M(j��n)���{(di��o)����ʹ��Virtex-5���������ṩ�I(y��)���I(l��ng)�ȵ����ܣ�ͬ�r(sh��)�܉����Ƚ���й©������Ķ��������o�B(t��i)���ġ�
���⣬�µ� 6-LUT ߉�Y(ji��)��(g��u)��ÿ��(g��)LUT ���ں��˸����߉�K��ʹ�����^�ٵľֲ����B��(ji��)�c(di��n)���ٵĸ���ݹ�(ji��)�c(di��n)��߉����֮�g����������߉�ӴΣ��Ķ��s����·�����t���@�N�µČ�(du��)�Q����߀ʹ����߉֮�g���B�Ӹ���ֱ�ӣ��@�M(j��n)һ�������˲�����ݡ�VCCINT�����Ĺ��늉����F(xi��n)����1.0V�������@Щ���ض������ڿ��w��(d��ng)�B(t��i)���ĵĽ��͡�Virtex-4 ϵ�еijɹ����V�҂����ܶ�̎������ܺ��Ŀ�����ϵ�y(t��ng)�O(sh��)Ӌ(j��)�еăɂ�(g��)ͬ����Ҫ�ļs���l������ˣ��҂�����Ҫ�����ܣ�Ҳ��Ҫ���ġ��҂���(du��) Virtex-5 ��߉�Y(ji��)��(g��u)�M(j��n)���ˏصĸ��M(j��n)���Ա�������65 �{�����ŘO�����ӵ�CMOS ��ˇ���Y(ji��)�����Q���������ֹ������ߵĽY(ji��)��(g��u)��ϵ�y(t��ng)�r(sh��)��l�ʳ��^550 MHz����90 �{�� Virtex-4 ��ȣ�Virtex-5 ���o�B(t��i)���Ĵ��w�ஔ(d��ng)������(d��ng)�B(t��i)�������ٽ�����35%����������ǰ݅һ�ӣ�Virtex-5 ϵ����һ���ṩ��������(j��)FPGA ϵ���y�ԱȔM�ĵ��Ľ�Q������
�m����ϵ�y(t��ng)���ɵĸ�(j��)����
��Virtex-5 ϵ���У��҂�?c��)�ÿ��(g��)�r(sh��)犹����ܵ� (CMT) �м�����һ��(g��)�i��h(hu��n)(PLL)���F(xi��n)��ÿ��(g��)�r(sh��)犹����ܵ����Ѓɂ�(g��)��(sh��)�֕r(sh��)犹����� (DCM) ��һ��(g��)PLL����� CMTͬ�r(sh��)�ṩ�˃ɂ�(g��)��(sh��)�����ģ�M���(y��u)���ԣ���(sh��)�֕r(sh��)犹��������߂�ď�(qi��ng)���Ķ���Ժ;��_���f�������������cģ�MPLL �����Ľ��Ͷ���(d��ng)���ܡ�ԓϵ����������ߵ���̖(h��o)�߂�����(g��)���Ԯa(ch��n)���Ͳ���550MHz �r(sh��)犵�CMT �� �Ķ�֧��Virtex-5 ��߉��ģ�K���ܡ�
ͬ���p�˿� block RAM ��һ��(g��)��Ҫ�Ĺ��܉K��ÿ��(g��) block RAM �Ĵ�С�ѽ�(j��ng)���ӵ�36 Kb����������Ԍ��������ɂ�(g��)�Ϊ�(d��)�� 18-Kb block RAM����(sh��)��(j��)�������ȏ�1 λ��36 λ�ǿɾ��̵ġ��ں�(ji��n)���p�˿�ģʽ��һ��(g��)�˿ڌ�����һ��(g��)�˿��x������(sh��)��(j��)�������ȿ��Ը��_(d��)72 λ����Ч�ؼӱ��˔�(sh��)��(j��)��������߀�����P(gu��n)�]δ��ʹ�õ�18-Kb block RAM �Թ�(ji��)ʡ���ġ�
ԓblock RAM ���м��ɵ� FIFO ����߉���Ķ���(ji��n)�����ڸ��_(d��) 550 MHz �r(sh��)��l�����\(y��n)�еĮ�������ͬ���� FIFO ���O(sh��)Ӌ(j��)��ͬ�r(sh��)�o�������κ�߉�YԴ��
72 λ���� block RAM �F(xi��n)��߀����64-bit �ęz�e(cu��)�`�ͼm�e(cu��) (ECC) ����߉������ڼ��ɵ� FIFO ֧�ֹ��ܣ�ԓ���ɻ� ECC ����˴惦(ch��)�������ܣ�ͬ�r(sh��)��������Щ�͂��y(t��ng)�Ļ��ڽY(ji��)��(g��u)�Ľ�Q�������P(gu��n)�ijɱ�����߀����ʹ�Ì��� ECC ߉������(qi��ng)�ⲿ�惦(ch��)���ӿڡ�
�҂������Ƴ��� ChipSyncTM ���g(sh��)���������(qi��ng)�ͺ�(ji��n)�����c�ⲿ�O(sh��)���������ⲿ�惦(ch��)��������DDR��DDR2�� QDR II ��RLDRAM II�����B�ӡ������҂� LX50T �����Ĵ惦(ch��)���_�l(f��)ϵ�y(t��ng) (ML561)������ͨ�^Ӳ���(y��n)�C�Č�(sh��)�Å����O(sh��)Ӌ(j��)��ԓ�����O(sh��)Ӌ(j��)��������Ŀǰ���е������惦(ch��)���g(sh��)��
�� DSP �I(l��ng)���҂��Ƴ���һ��(g��) 25 x18-bit �ij˷�������Ҫ���ڸ���Ч�ʵĸ��c(di��n)�O(sh��)Ӌ(j��)���@Щ DSP48E ߉Ƭ�����M(j��n)��ֱ�Ӽ�(j��)(li��n)���Ķ��܉��ڔ�(sh��)�֞V����ҕ�l�V����(y��ng)���Ќ�(sh��)�F(xi��n)���ߵ����ܡ�ֱ�Ӽ�(j��)(li��n)߀���Թ�(ji��)ʡ���� - ��������(j��ng)��(zh��ng)�������^���҂����Խ���40%�Ĺ��ġ�Virtex-5 SelectIO? ���g(sh��)�^�m(x��)�ژI(y��)�籣���I(l��ng)�ȵ�λ���������_��(sh��)�H�϶�֧��Ŀǰʹ�õ����� I/O ��(bi��o)��(zh��n)�������ṩ���_(d��)1.25 Gbps �� LVDS �� 800 Mbps �Ćζ� I/O ���ܡ������ṩ�ɾ���ݔ�����t�����L(zh��ng)75ps �� �� IDELAY �x�(xi��ng)�⣬ ���Ƴ���ODELAY �x�(xi��ng)�� FPGA ��ݔ�����ṩ��ͬ�Ӿ���(x��)�����ȡ�ÿ��(g��)���ܶ��������������������_���M(j��n)�ІΪ�(d��)���̡�IODELAY ������һ��(g��)��Ҫ�����ԣ���������(qi��ng)��(du��)����Դͬ����(sh��)��(j��)�͕r(sh��)犵Ŀɿ��l(f��)�ͺͽ��ա�Ŀ��(bi��o)��(y��ng)�ð����弉(j��)ƫб�a(b��)����������λ��(du��)��(zh��n)�Լ���(sh��)��(j��)�͕r(sh��)���̖(h��o)�Č�(du��)��(zh��n)��ԓ�����܉� LVDS I/O ��(sh��)�F(xi��n)ÿ��(du��)���_���_(d��)1.25 Gbps �����ʡ�Virtex-5 LXT ��SXT �� FXT ����ͬ���ṩ��Ƕ��ʽ�����հl(f��)�� - ��������ߵ� LXT �����а������@�N�հl(f��)���Ĕ�(sh��)Ŀ��Ȼ���_(d��) 24 ��(g��)�����_�l(f��)���ٴ����հl(f��)���ĵ��Ĵ� RocketIO? ���g(sh��)�r(sh��)���҂�?c��)ڽ����ķ���Ͷ������ľ������?.2Gbps�ķ�ֵ�����£�LXT RocketIO �հl(f��)���Ĺ��ĵ���100 mW��ʹ��ɞ�����FPGA �a(ch��n)Ʒ�й�����͵��հl(f��)������醈D4����

�D4 - RocketIO GTP �հl(f��)��
ÿ��(g��) Virtex-5 LXT RocketIO �հl(f��)�����ǿɾ��̵ģ����Ԍ�(sh��)�F(xi��n)���N���ʣ�֧�ָ��N���И�(bi��o)��(zh��n)���҂�����ÿ��(g��)��(bi��o)��(zh��n)��������̫�W(w��ng)��HD/SDI������RapidIO��FibreChannel �� Aurora���Ƴ����·��IP������҂��A(y��)Ӌ(j��)�� PCI Express (PCIe)���c(di��n)��(y��ng)�õ��ձ��ԣ���Ӳ��߉�м����������� PCIe ���c(di��n)�f(xi��)�h��Virtex-5 LXT PCIe ���c(di��n)ģ�K��ȫ���� PCIe ��(bi��o)��(zh��n)Ҏ(gu��)����1.1 �汾������֧��x1��x2��x4 �� x8��ͨ����(sh��)�F(xi��n)����������ʽӲ IP ��(ji��)ʡ��߉�YԴ����������������ռ��� PCIe ��(y��ng)�õ����ܡ���(du��)�� x4 PCIe ͨ���Č�(sh��)�F(xi��n)���ԣ��^֮ܛ IP ��(sh��)�F(xi��n)������Virtex-5 PCIe��ϵ�y(t��ng)ģ�K��(ji��)ʡ�� LUT ��(sh��)Ŀ���_(d��) 8,500��(g��)��Virtex-5 �����ṩ�˸����С��I/O bank���ⲿ I/O bank ��������ߵ���̖(h��o)�к��а˂�(g��) bank ��Ҳ��(j��ng)�^���İ��ţ��Ķ����� PCB ��������ijЩ��r�¿��Թ�(ji��)ʡ PCB ��IJ����Ӽ�(j��)��
���˱��Cȡ�� FPGA �I(y��)����ѵ�ͬ���ГQݔ�� (SSO) ���ܣ� ���Ҍ�(sh��)�F(xi��n)FPGA �I(y��)����õ���̖(h��o)������ (SI) ��Q���������� Virtex-5 ���������� Xilinx��ϡ����X���g(sh��)�M(j��n)�в��_�����Č�(du��)�R���@�N�����_��ÿ��(g��) I/O ���_�����Ա��Դ���_�͵����_�o�ܰ������Ķ�ʹ����h(hu��n)늸���С���M(j��n)���������̖(h��o)�����ԡ�
�Y(ji��)Փ
ϣ����ǰ��Ľ�B�܉������õ��˽�Virtex-5 �������䱳����O(sh��)Ӌ(j��)��(d��ng)���҂��dz�ϣ��ϵ�y(t��ng)�O(sh��)Ӌ(j��)���܉�Ӽ{�@�Nȫ�µļܘ�(g��u)���҂�ϣ������������һ��ϵ�y(t��ng)�܉�� Virtex-5 ����(qi��ng)�����ܺ����Ы@�棬�����ď�(f��)�s�O(sh��)Ӌ(j��)������һ��(g��)�µĸ߶ȡ�
]]>����(bi��o)��(zh��n)��Ԫ�˿ɾ�������������һ����ζ��ʹASIC���ӱ��ˣ�����FPGA����ʡ늡����ǣ����O(sh��)Ӌ(j��)�ˆT���p���ă�(y��u)�c(di��n)�Y(ji��)����һ��ͨ�^ȥ��FPGA��һЩ���ܣ��O(sh��)Ӌ(j��)�ˆT�ɜp�ٳɱ����_�l(f��)�r(sh��)�g���������`���ԡ��Еr(sh��)�҂��ѽ�(j��ng)���y�ж�ʲô��Ƕ��ɾ���߉��ASIC��ʲô��Ƕ���(bi��o)��(zh��n)��Ԫ��FPGA������Ӎ�ѽ�(j��ng)���������܉��ṩ�κα�����FPGA��ASICоƬ����In-Stat��˾�ķ�����Max Baron�f��������FPGA/ASIC�ı�����60/40���@�����p��FPGA�Ј�(ch��ng)����
ASICǶ��ɾ���߉��Ԫ
Actel��ȡ���փ�·�đ�(zh��n)�ԡ��@�ҷ��۽zFPGA����(y��ng)�̷���(w��)�ڂ��y(t��ng)��FPGA��(y��ng)�ã��a(ch��n)Ʒ��MX��SX������eXϵ��������Actel����������cASIC�����̽Y(ji��)�˵�Ӌ(j��)������SoC�O(sh��)Ӌ(j��)�ṩǶ��ʽFPGA IP�����҂�Ŭ��ʹδ����ASSP��ASIC����(y��ng)���ЙC(j��)��(hu��)������M(j��n)���Ј�(ch��ng)������Ƕ��ʽ��(n��i)�˫@�ø��L(zh��ng)���Ј�(ch��ng)�����ڡ���Ƕ��ʽFPGA���F(tu��n)���O(ji��n)Yankin Tanurhan�f��
VHDL�Z����һ�N�����·�O(sh��)Ӌ(j��)�ĸ�(j��)�Z�ԡ�����80����ĺ��ڳ��F(xi��n)�������������(gu��)��(gu��)�����_�l(f��)��������܊�Á�����O(sh��)Ӌ(j��)�Ŀɿ��ԺͿs�p�_�l(f��)���ڵ�һ�Nʹ�÷����^С���O(sh��)Ӌ(j��)�Z�ԡ����ǣ���������һ���̶��ϝM���ˮ�(d��ng)�r(sh��)���O(sh��)Ӌ(j��)������������1987��ɞ�ANSI/IEEE�Ę�(bi��o)��(zh��n)��IEEE STD 1076-1987����1993����M(j��n)һ����ӆ��׃�ø�����䣬�ɞ�ANSI/IEEE��ANSI/IEEE STD 1076-1993��(bi��o)��(zh��n)��Ŀǰ�������(sh��)��CAD�S�̳�Ʒ��EDAܛ�����������@�N��(bi��o)��(zh��n)��
2.��(du��)CPLD/FPGA�ĽY(ji��)��(g��u)���^��Ϥ��
�����@�ɂ�(g��)�l���������O(sh��)Ӌ(j��)���^�����x���m��(d��ng)?sh��)������Ķ�����O(sh��)Ӌ(j��)�Ŀɿ��ԡ���������������ʼ��s���O(sh��)Ӌ(j��)�����ڡ�������һ��(g��)�ش�Ć��}�����ڣ������Įa(ch��n)Ʒ�����Ą�(d��ng)����Ҫ���������CPLD/FPGA�r(sh��)���㌢��Ҫ����ݔ��ԭ��D�������ò�ͬ�������ڽ����@�N��(j��ng)��(zh��ng)�h(hu��n)�����Ǖ�(hu��)��(j��ng)���l(f��)���ġ��^����?y��u)�����߮a(ch��n)Ʒ�����ܻ����ǽ��ͮa(ch��n)Ʒ����r(ji��)����߱����Եȵȣ�����(hu��)���]�x�ò�ͬ����������(du��)��������ֻ������һ��(g��)�Q������(du��)�҂����ԅs��Ҫ�҂������������Ѫ����
2.ʹ�þ��g���߾��gԴ�ļ���HDL�ľ��g���кܶ࣬ACTIVE��˾��MODELSIM��˾��SYNPLICITY��˾��SYNOPSYS��˾��VERIBEST��˾�ȶ����Լ��ľ��g����
3.(���x���E�����ܷ��档��(du��)��ijЩ�˶��ԣ������@һ���ƺ��ǿ��пɟo�ġ����nj�(du��)��һ��(g��)�ɿ����O(sh��)Ӌ(j��)���ԣ��κ��O(sh��)Ӌ(j��)��ö��M(j��n)�з��棬�Ա��C�O(sh��)Ӌ(j��)�Ŀɿ��ԡ����⣬��(du��)������һ��(g��)��(d��)�����O(sh��)Ӌ(j��)�(xi��ng)Ŀ���ԣ������ļ����ṩ������C�����O(sh��)Ӌ(j��)�������ԡ�
4.�C�ϡ��C�ϵ�Ŀ�������ڌ��O(sh��)Ӌ(j��)��Դ�ļ����Z���D(zhu��n)�Q�錍(sh��)�H���·�������Ǵ˕r(sh��)߀�]����оƬ���γ��������·���@һ���ͺ����ǰ��˵��X���е��·����ԭ��D��--�@���ҵĂ�(g��)���^�c(di��n)���ƺ��ںö��īI(xi��n)�ж��]���ᵽ���C�ϡ��Ĝ�(zh��n)�_���x�����٣����x�^�Ďױ����о͛]�С����@һ������KĿ���������T�·��(j��)�ľW(w��ng)����Netlist����
5.���֡��������@һ����Ŀ�����������ڟ���������Programming���ľ����ļ������@һ�������õ���4�����ɵľW(w��ng)��������(j��)CPLD/FPG�S�̵������������Y(ji��)��(g��u)���M(j��n)�в��֡��������@�ͺ������O(sh��)Ӌ(j��)PCB�r(sh��)�IJ��ֲ���һ�ӡ��Ȍ�����(g��)�O(sh��)Ӌ(j��)�е��T����(j��)�W(w��ng)���ă�(n��i)�ݺ������ĽY(ji��)��(g��u)�����������ض���λ��Ȼ���ڸ���(j��)�W(w��ng)�����ṩ�ĸ��T���B�ӣ��Ѹ���(g��)�T��ݔ��ݔ���B���������������һ��(g��)�����̵��ļ����@һ��ͬ�r(sh��)߀��(hu��)��һЩ�r(sh��)����Ϣ��Timing��������������O(sh��)Ӌ(j��)�(xi��ng)Ŀ��ȥ���Ա��c��������档