Linux內核兩個部分共同組成的一個操作系統。該系統中所有組件的源代碼都是自由的,可以有效保護學習成果,因而在嵌入式領域得到了廣泛的應用。
FPGA是英文Field Programmable Gate Array的縮寫,即現場可編程門陣列,該器件是作為專用集成電路ASIC (Application Specific Integrated Circuit)領域中的一種半定制電路而出現的,它的出現既解決了定制電路的不足,又克服了原有可編程器件門電路數有限的缺點。在通信行業、傳輸網、醫療儀器、各種電子儀器、安防監控、電力系統、汽車電子以及消費類電子中都大面積使用。隨著產品研發周期的逐步縮短,定制型產品的開發使FPGA在后面的應用面越來越廣。例如在2G和3G通信,以及以后的4G通信和wimax等等通信類設備中,它與DSP、MPU一起將大量出現在其中。
S3C2410微處理器是一款由Samsung為手持設備設計的低功耗、高度集成的微處理器,采用272腳FBGA封裝,內含一個ARM920T內核和一些片內外圍設備。在時鐘方面,該芯片集成了一個具有日歷功能的RTC和具有PLL (MPLL和UPLL)的芯片時鐘發生器。MPLL產生的主時鐘能夠使處理器工作頻率最高達到203MHz。這個工作頻率能夠使處理器輕松運行于Windows CE,Linux等操作系統并進行較為復雜的信息處理。為此,本文以S3C2410上使用Altera公司的EP2S30F67214為例,系統地介紹了在Linux系統環境下的FPGA的驅動方法。
1 基本原理
Linux下的設備驅動程序通常是一個存在于應用程序和實際設備間的軟件層。許多設備驅動都是與用戶程序一起發行的,可以幫助配置和存取目標設備。
在Linux下驅動FPGA,其本質上就是字符設備的驅動,慣例上它們位于/dev目錄。
1.1 主次編號
在內核中,dev_t類型(在中定義)用來持有設備編號。通常2.6內核版本限制在255個主編號和255個次編號。
建立一個字符驅動時,需要做的第一件事是獲取一個或多個設備編號。其必要的函數是regis-ter_chrdev_region,設計時可在中聲明:
int register_chrdev_region(dev_t first,unsigned int count,char*name);
如同大部分內核函數一樣,如果分配成功,register_chrdev_region的返回值將是0。出錯時,則返回一個負的錯誤碼,但不能存取請求的區域。
1.2 重要數據結構
注冊設備編號僅僅是驅動代碼必須進行的諸多任務中的第一個。驅動操作包括三個重要的內核數據結構,稱為file_operations、file和inode。其中,對于FPGA驅動來說,最值得關注的是文件操作(file_operations)。
file_operation結構是一個用字符驅動方式建立設備編號和設備操作的連接結構,定義在.是一個函數指針的集合。每個打開文件與它自身的函數集合相關,這些操作大部分可由系統調用,例如:open(),read ()等等。典型的file_operation結構可用FPGA設備列表所示,其代碼如下:

第一個file_operations元素根本不是一個操作,它是一個指向擁有這個結構的模塊指針,或用來在操作使用時阻止模塊被卸載,它也是在中定義的宏;
llseek主要用于改變文件中的當前讀/寫位置,同時可將新位置作為(正的)返回值。其定義如下:
loff_t(*llseek) (struct file*,loff_t,int);
ioctl可為系統調用提供一個發出設備特定命令的方法。如果設備不提供ioctl方法,那么,對于任何未事先定義的請求,系統調用將返回一個錯誤。定義如下:
int(*ioctl) (struct inode*,struct file*,unsigned int,unsigned long):
1.3 設備注冊
內核在內部將使用struct cdev類型結構來代表字符設備。在內核調用設備操作前,代碼應當包含。而如果想將cdev結構嵌入設備特定的結構中,則應當初始化已經分配的結構,其使用的代碼為:
void cdev_init(struct cdev*cdev,structfile_operations*fops);
1.4 open和release
open主要用于提供驅動初始化,在大部分驅動中,open應當檢查設備特定的錯誤(例如設備沒準備好,或者類似的硬件錯誤),但是,其第一步常常是確定打開哪個設備。open的原代碼為:
int(*open) (struct inode*inode,structfile*flip);
1.5 讀/寫操作
讀和寫都是進行類似的任務,就是從設備到應用程序代碼的數據拷貝。因此,它們的原代碼比較相似:
ssize_t read(struct file*flip,char__user*buff,size_t count,loff_t*offp);
ssize_t write(struct file*filp,const char__user*buff,size_t count,loff_t*offp);
read的任務是從設備拷貝數據到用戶空間(使用copy_to_user),而write方法則是從用戶空間拷貝數據到設備(使用copy_from_user)。

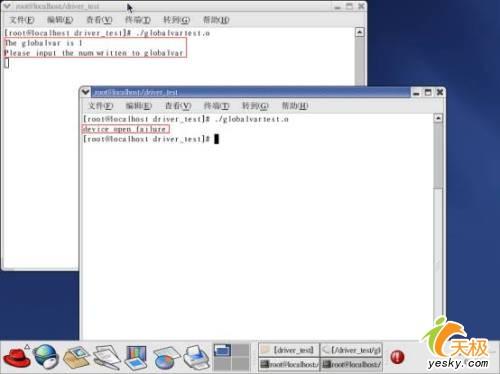
圖1所示是用read參數表示一個典型讀的實現過程。
2 硬件電路
通常在大容量存儲項目中,S3C2410處理器一般作為主CPU,可對EP2S30F67214進行擴展,以使系統具有拍攝、存儲、下載、I/O口擴展的功能。由于FPGA的高速處理能力和易擴展性,ARM與FPGA的結合使用,將在嵌入式系統領域占據主導地位。
本項目中的ARM主要讀取FPGA的數據,然后進行數據處理并送給上位機。其ARM處理器與FPGA的連接關系如圖2所示,其主要連接有32位寬數據線、27位寬地址線以及讀、寫、中斷和片選控制線等。

在S3C2410中,nGPCS4的物理地址為0x2000000—0x28000000,共計128MB的靜態物理空間。中斷方式為下降沿有效。
3 編程實現
3.1 設備驅動初始化
初始化模塊在內核啟動時主要負責初始化FPGA工作。其實現由module_init () 和module_exit ()兩部分組成。其代碼如下:

3.2 異步中斷通知
在應用程序中,可用如下代碼獲得中斷響應:
signal (SIGIO,test_handler);/*test_handler為函數名字*/
fcntl(fa,F_SETOWN,getpid ());
oflags=fcntl(fa,F_GETFL);/*fd為打開設備返回值*/
fcntl (fd,F_SETFL,oflags∣FASYNC);/*fd為打開設備返回值*/
應當注意的是,不是所有的設備都支持異步通知。應用程序常常假定異步能力只對socket和tty可用。
3.3 地址映射
在Linux設備驅動程序開發過程中,由于驅動程序操作的都是設備的虛擬地址,因此,要使驅動程序對虛擬地址的操作反映到正確的設備上,還需要通過內存管理單元MMU來將設備的虛擬地址映射到正確的物理地址上去,從而保證驅動程序對設備的虛擬地址的操作,也就是要對其相應的物理地址進行操作。使用內存映射的好處是處理大文件時,其速度明顯快于標準文件I/O,這樣無論讀和寫,都少了一次用戶空間與內核空間之間的復制。在用戶空間對FPGA設備的訪問可通過內存映射來實現。FPGA可以看作是硬件連接在S3C2410微處理器的片選信號nGPCS4上的一段物理地址的尋址。因此,必須先把物理地址映射到虛擬地址空間,然后才能對該段地址進行讀/寫。通常用戶可用如下代碼關聯FPGA的地址:
fpga_base=ioremap(FPGA_PHY_START,FPGA_PHY_SIZE);
4 結束語
本文系統的介紹了ARM基于Linux平臺下的FPGA的驅動開發方法,并通過開發用戶程序,實現了數據的處理和傳輸,從而實現了FPGA在嵌入式領域的廣泛應用。
]]>












.jpg)